1.2. 继承与类型层次结构
C++ 中的类型层次结构具有双重目的。一方面,表达对象之间的关系;另一方面,能够从较简单的类型组合出更复杂的类型。这两种用途可通过继承来实现。
继承的概念在 C++ 的类和对象使用中处于核心地位,继承能将新类定义为现有类的扩展。当派生类从基类继承时,会以某种形式包含了基类中的所有数据和算法,并添加了自身的一些内容。在 C++ 中,区分两种主要的继承方式非常重要 —— 公有继承和私有继承。
公有继承会继承类的公有接口,同时也继承其实现 —— 基类的数据成员也成为派生类的一部分。但接口的继承是公有继承的关键特征:派生类的公有接口中包含了基类的公有成员函数,从而形成“is-a”的关系。
公共接口就像一份约定 —— 类的使用者承诺,该类支持某些操作、维护某些不变量,并遵守指定的限制。通过公有继承基类,将派生类也绑定到同一份约定上(此外,如果决定定义其他公共接口,还需要包含对约定的扩展)。由于派生类同样遵守基类接口的约定,可以在代码中使用基类的地方使用派生类(尽管无法使用接口的扩展部分,在该上下文中代码只期望基类,此时并不了解相关的扩展),但基类的接口及其限制必须有效。
这通常表述为“is-a”原则 —— 派生类的实例同时也是基类的实例。然而,在 C++ 中对“is-a”关系的理解有时并不直观。例如,正方形是矩形吗?如果是,可以从 Rectangle 类派生出 Square 类:
class Rectangle {
public:
double Length() const { return length_; }
double Width() const { return width_; }
...
private:
double l_;
double w_;
};
class Square : public Rectangle {
...
};有一些不对劲的地方 —— 派生类有两个表示尺寸的数据成员,但实际上只需要一个。我们必须以某种方式强制它们保持一致。这看起来问题还不大 —— Rectangle 类的接口允许长度和宽度为任意正值,而 Square 类施加了限制。但问题比这更严重的是 —— Rectangle 类有一个约束,允许用户将两个尺寸设置为不同的值。这种约束可以很明确地体现出来:
class Rectangle {
public:
void Scale(double sl, double sw) {
// 缩放尺寸
length_ *= sl;
width_ *= sw;
}
...
};现在,有一个公共方法,可以扭曲矩形,改变其长宽比。和其他公共方法一样,这个方法派生类也会继承,因此 Square 类现在也拥有了这个方法。通过使用公有继承,声明的 Square 对象可以在需要 Rectangle 对象的地方使用,甚至无需知道它是一个 Square。显然,这是一个无法兑现的承诺 —— 当类型层次结构的使用者,试图改变正方形的长宽比时无法做到。我们可以选择忽略调用或在运行时报告错误。无论哪种方式,都违反了基类所提供的约定。唯一的解决方案是:在 C++ 中,正方形不是一个矩形。通常,矩形也不是正方形 —— 如果 Square 接口包含了一些无法在从 Square 派生 Rectangle 时的约定保证,同样不成立。
类似地,如果鸟类接口包含飞行能力,那么企鹅在 C++ 中就不是鸟。所以,正确的设计通常包括一个更抽象的基类 Bird,不会做出派生类无法履行的承诺(例如,Bird 对象并不保证它能飞行)。然后,创建中间基类,如 FlyingBird 和 FlightlessBird,从共同的基类派生,并作为更具体类(如 Eagle 或 Penguin)的基类。这里的重要教训是:在 C++ 中,企鹅是否是鸟取决于如何定义鸟,或者用 C++ 的术语来说,取决于 Bird 类的公共接口是什么。
由于公有继承意味着“is-a”关系,因此允许在同一类型层次结构中不同类的指针和引用之间进行广泛的转换。首先,从派生类指针转换为基类指针是隐式的(引用也是如此):
class Base { ... };
class Derived : public Base { ... };
Derived* d = new Derived;
Base* b = d; // 隐式转换这种转换始终有效,派生类的实例同时也是基类的实例。相反的转换也可以有,但必须显式进行:
Base* b = new Derived; // *b 实际上是 Derived 类型
Derived* d = b; // 无法编译,不允许隐式转换为 Derived*
Derived* d1 =
static_cast<Derived*>(b); // 显式转换之所以转换非隐式,是因为其基类指针需要指向一个派生类对象时才有效(否则行为未定义)。因此,开发者必须使用 static_cast 显式地断言:通过程序逻辑、先前的测试或其它方式,已知该转换是有效的。如果不能确定转换是否有效,存在一种更安全的方法可以尝试转换而不会导致未定义行为;我们将在下一节中进行介绍。
基类和派生类指针之间的静态(或隐式)转换,并没那么简单。对象的第一个基类始终与派生对象本身的地址相同,但情况随后会变得更复杂。对于具有多个基类的派生类,通常对内存布局没有统一的标准要求:
class Base1 { ... };
class Base2 { ... };
class Derived : public Base1, public Base2 { ... };大多数编译器会先布局基类,然后是派生类的数据成员:
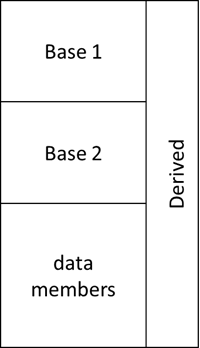
从图 1.1 可以明显看出,基类与派生类之间的指针转换通常涉及偏移量的计算:
// Example 01_cast.C
Derived d;
Derived* p = &d;
std::cout << "Derived: " << (void*)(p) <<
" Base1: " << (void*)(static_cast<Base1*>(p)) <<
" Base2: " << (void*)(static_cast<Base2*>(p)) <<
std::endl;程序输出的内容类似于:
Derived: 0x7f97e550 Base1: 0x7f97e550 Base2: 0x7f97e560Base1 对象与 Derived 对象位于相同的地址,而 Base2 则以一个偏移量开始(例子中是 16 字节)。看起来转换只是一个简单的计算:如果有一个指向 Derived 的指针,并想要转换为 Base2,那么加上 16 即可。基类之间的偏移量在编译时就已经知道,编译器也了解它所使用的布局。指针偏移计算通常在硬件层面实现(所有现代 CPU 都支持这些计算,不需要单独的加法指令),感觉并不复杂。
那么,指针是空指针(null)该怎么办?空指针的值为 0。如果应用相同的转换规则,就会得到 16(即 0x10),这样一来,对空指针的检查就会失败:
void f(Base2* p) {
if (p != nullptr) do_work(*p);
}
Derived* p = nullptr;
f(p); // 尝试解引用 0x10 吗?这会带来严重的问题,因此需要确定空指针在转换后应保持为空:
Derived* p = nullptr;
std::cout << "Derived: " << (void*)(p) <<
" Base1: " << (void*)(static_cast<Base1*>(p)) <<
" Base2: " << (void*)(static_cast<Base2*>(p)) <<
std::endl;所有指针的值相同(即为 0):
Derived: 0x0 Base1: 0x0 Base2: 0x0这是实现转换的唯一方式,但其表示从 Derived* 到 Base* 的隐式转换,在内部会隐含地结合一个空指针检查的条件运算。
C++ 中的另一种继承方式是私有继承,派生类不会扩展基类的公共接口 —— 所有基类的方法在派生类中都变为私有。派生类必须从头开始创建自己的公共接口,相当于一张白纸。此时不再假设派生类的对象可以替代基类对象使用。派生类从基类继承到的是实现细节 —— 其方法和数据成员都可以在派生类中用来实现自身的算法。因此,私有继承通常认为实现了一种“has-a”关系 —— 派生对象内部包含了一个基类的实例。
私有派生类与其基类的关系,类似于一个类与其数据成员之间的关系。后一种实现技术称为组合 —— 一个对象由任意数量的其他对象组合而成,这些对象都作为其数据成员。在没有特殊理由的情况下,应优先使用组合而非私有继承。那么,使用私有继承的理由可能有哪些呢?有几种可能性。首先,可以在派生类内部,通过 using 声明重新暴露基类的某个公共成员函数:
class Container : private std::vector<int> {
public:
using std::vector<int>::size;
...
};这在少数情况下可能有用,等同于一个内联的转发函数:
class Container {
private:
std::vector<int> v_;
public:
size_t size() const { return v_.size(); }
...
};其次,指向派生类对象的指针或引用可以转换为指向基类对象的指针或引用,但这种转换只能在派生类的成员函数内部进行。相比之下,组合可以通过取数据成员的地址来实现类似的功能。目前,还没有看到使用私有继承的充分理由,所以,通常的建议是优先使用组合。但接下来的两个原因更为重要,一个都可能足以成为使用私有继承的充分动机。
使用私有继承的一个充分理由与组合对象或派生对象的大小有关,我们经常会遇到一些只提供方法但没有数据成员的基类。这样的类本身没有数据,理论上不应占用内存空间。但在 C++ 中,每个对象都必须具有非零大小。因为语言要求两个不同的对象或变量,必须具有不同且唯一的地址。通常,如果依次声明两个变量,第二个变量的地址等于第一个变量的地址加上第一个变量的大小:
int x; // 在地址 0xffff0000 处创建,大小为 4 字节
int y; // 在地址 0xffff0004 处创建为了避免需要特殊处理零大小的对象,C++ 会为一个空对象分配大小为 1。这样的对象可用作类的数据成员它至少会占用 1 字节(后续数据成员的对齐要求可能会使这个值更大)。这属于内存浪费 —— 这些空间永远不会使用。另一方面,如果一个空类用作基类,则没有要求该基类部分必须具有非零大小。虽然整个派生类对象必须具有非零大小,但派生对象本身、其基类部分以及其第一个数据成员的地址可以全部相同。因此,在 C++ 中,为一个空基类不分配内存空间是合法的,即使 sizeof() 对该类返回 1。尽管合法,但这种“空基类优化”(Empty Base Optimization, EBO)并非强制要求,会视为一种优化,大多数现代编译器都会执行这种优化:
class Empty {
public:
void useful_function();
};
class Derived : private Empty {
int i;
}; // sizeof(Derived) == 4
class Composed {
int i;
Empty e;
}; // sizeof(Composed) == 8如果创建大量派生对象,通过空基类优化节省的内存可能会非常可观。
使用私有继承的第二个可能原因与虚函数有关,这将在下一节中详细介绍。