8.1. 点亮像素
大约 30 年前,在那个技术自由奔放的 90 年代末期,作者本人曾投入大量时间进行代码优化 —— 目标是让程序在尽可能少的资源消耗下,以最快的速度运行,并在屏幕上呈现出令人惊叹的旋转图形(还包括滚动等其他视觉效果,虽与本文重点无关,但也极具挑战性)。
这些被称为“演示程序”(demos 或 intros)的小型应用程序,通常依托扎实的数学基础和高度精炼的自研图形引擎,来实现令人目眩的视觉效果。在那个还没有 DirectX 来接管底层细节的时代,所有工作都必须亲自动手完成:从像素颜色的计算、调色板的设置,到 CRT 显示器的垂直回扫控制、前后缓冲区的切换等等,全都依赖于当时标准 C++ 的能力,以及在关键时序路径上手工编写的汇编代码。
其中最基本、也是最频繁调用的功能就是在屏幕上绘制单个像素。其最简单的实现形式如下所示:
void putpixel(int x, int y, unsigned char color) {
unsigned char far* vid_mem = (unsigned char far*)0xA0000000L;
vid_mem[(y * 320) + x] = color;
}这里我就不赘述诸如 30 年前的段地址/偏移量内存机制这类底层细节了 —— 虽是那个时代的标志性特征,但对理解本章核心思想并非必需。
让我们设定如下背景:
- 你正在使用 DOS 系统(1994 年,在东欧一些偏远地区,几乎所有的 PC 用户仍在使用 DOS —— 向那 0.1% 的早期 Linux 用户致敬)。
- 你使用的是特殊的 0x13 图形模式(当时几乎所有游戏和演示程序都采用这个模式,因为它能以神秘的 320×200 分辨率显示 256 色。至于为何是这个分辨率和颜色数,恐怕只有当年 IBM 的工程师才能解释清楚)。
在这样的环境下,如果你往显存段地址 0xA000 的特定偏移位置写入一个字节,显卡就会根据公式计算出的坐标点亮对应的像素点。
经过多次尝试与优化,这位开发者意识到:当前的例程还不够高效,仍有进一步提升的空间。
请耐心听我继续讲述。那时市面上流行的“平价编译器”(也就是你在本书第 2 章提到的那种从软盘复制来的编译器)生成的代码大致如下所示(如截图所示):
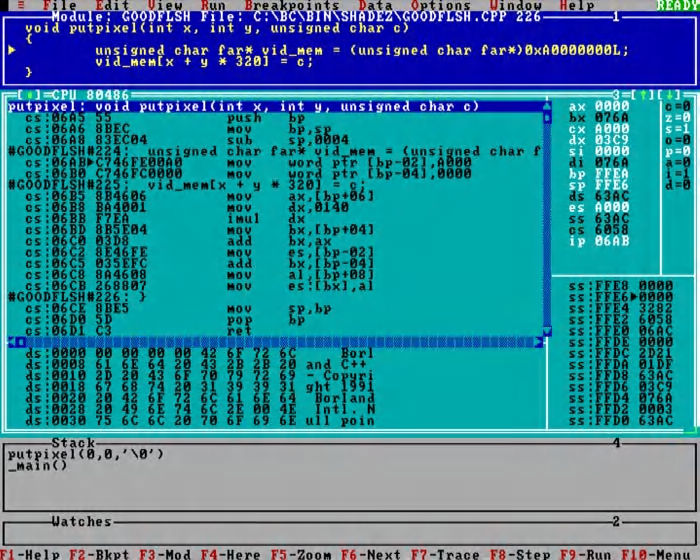 图 8.1 —— 30 年前大家最喜欢的 Turbo 调试器
图 8.1 —— 30 年前大家最喜欢的 Turbo 调试器从今天的视角来看,这段代码确实显得“狂野”而原始,但它所承载的历史意义远大于其技术复杂度。别急着下结论 —— 我们稍后将揭示这段代码背后的设计逻辑。
还记得我们刚才提到的那个观点吗?当时的编译器并不总能生成最优代码。接下来,我们就花一点时间仔细审视它。尤其是从如今已日渐稀少的汇编语言专家角度来看,他们可能会立刻指出:编译器的表现其实比我们预想的要好得多。
下面就是编译器为 putpixel 例程生成的汇编代码:
putpixel proc near
push bp ; Save the base pointer on the stack
mov bp, sp ; Set the BP to the current stack pointer
sub sp, 4 ; Reserve 4 bytes for local variables
mov word ptr [bp-2], 40960 ; Store 0xA000 at [bp-2]
mov word ptr [bp-4], 0 ; Store 0 at [bp-4]
mov ax, word ptr [bp+6] ; Load the y-coordinate into AX
mov dx, 320 ; Load the screen width into DX
imul dx ; Multiply AX (y-coord) by DX (screen width)
mov bx, word ptr [bp+4] ; Load the x-coordinate into BX
add bx, ax ; Add y*screen width (AX) to BX (x-coord)
mov es, word ptr [bp-2] ; Load 0xA000 into ES
add bx, word ptr [bp-4] ; Final pixel address in BX
mov al, byte ptr [bp+8] ; Load the color value into AL
mov byte ptr es:[bx], al ; Light the pixel!
mov sp, bp ; Restore the stack pointer
pop bp ; Restore the base pointer
ret ; Return from the procedure对于不熟悉这种表示法的读者,方括号 [] 表示取括号内地址所指向的数据。因此,函数参数是通过栈帧指针(bp)偏移来访问的,具体如下:
- 像素的x坐标(来自[bp+4])
- 像素的y坐标(来自[bp+6])
- 要设置的颜色值(来自[bp+8])
这段代码确实存在大量不必要的内存存取操作 —— 这些数据本可以完全保存在寄存器中进行处理。此外,还有一些冗余的内存访问步骤完全可以跳过。当时的编译器生成的代码虽然便于调试,但远远谈不上高效。事实上,这种情况在现代编译器的 Debug 模式 下也依然存在:生成的代码性能与之类似。然而一旦切换到优化后的 Release 模式,现代编译器就能展现出惊人的优化能力,自动将变量放入寄存器、消除冗余操作,甚至重排指令以提升执行效率。
现代 CPU 是高度复杂的“怪兽” —— 在保护模式下运行时,使用乱序执行、指令流水线、分支预测等技术,使得底层性能分析变得极其困难。相比之下,老式机器要简单得多。或者,如果你在现代电脑上运行 DOS(例如通过 DOSBox),也能获得类似的体验。
尽管保护模式早在 80286 处理器时代就已引入,但 DOS 根本无法有效利用它(即使今天也不能)。因此,DOS 坚持使用最熟悉的实模式(real mode)。在该模式下,处理器只是简单地逐条执行指令,甚至连内存保护都没有。在实模式下,处理器只是逐条执行指令,甚至还有指令周期表详细说明每条指令所需的时钟周期https://zs3.me/intel.php。
经过大量时间翻阅这些周期表后,得出了一个关键结论:在当时的处理器上,一次乘法操作可能比两次位移加一次加法更耗时。
这并不是什么深奥的知识,全球成千上万的开发者都曾得出相同的结论。但在那个信息闭塞的年代,却觉得自己像是英雄一般,发现了这个“隐藏特性”。
考虑到屏幕宽度为 320 像素这一数值非常“友好”(它恰好等于 256 + 64),我们便可以利用位移和加法替代乘法运算,从而大幅提高速度。经过多轮优化,最终提出了以下稍作改进的版本:
void putpixel(int x, int y, unsigned char c) {
asm {
mov ax, 0xA000 // Load 0xA000 (VGA mode 13h) into AX
mov es, ax // Set ES to the video segment (0xA000)
mov dx, y // Load the y-coordinate into DX
mov di, x // Load the x-coordinate into DI
mov bx, y // Copy the y-coordinate into BX
shl dx, 8 // Multiply DX by 256 (left shift by 8 bits)
shl bx, 6 // Multiply BX by 64 (left shift by 6 bits)
add dx, bx // Add those, effectively multiplying y by 320
add di, dx // Add the calculated y to DI (pixel offset)
mov al, c // Load the color value into AL
stosb // Light the pixel
}
}虽然这并非理论上最优的实现方式,但它已经完全满足了我们当时的特定需求。
该版本大幅减少了直接内存访问(即便在当年这也被认为是低效的操作),并将原本耗时的 320 乘法运算(使用 imul 指令)替换为更高效的位移操作:将 x + y * 320 拆解为 y * 256 + y * 64。具体来说,通过 shl dx, 8 实现乘以 256,再通过 shl dx, 6 实现乘以 64,最后求和即可完成坐标偏移计算。这一改动使得总指令周期数显著低于原始的乘法操作。
这段优化经历也催生了一个根深蒂固的观念:如果追求极致性能,就必须亲手编写底层代码、深入汇编、掌控每一个时钟周期。
但让我们来做个有趣的思维实验 —— 跨越 30 年的技术演进,跳过数代编译器的发展历程。如果我们把当年那段原始 C++ 代码输入现代编译器(本文使用 Clang 18.1;GCC 的输出也非常类似,仅寄存器选择略有不同),又会得到怎样的结果呢?
putpixel(int, int, unsigned char):
movzx eax, byte ptr [esp + 12]
mov ecx, dword ptr [esp + 4]
mov edx, dword ptr [esp + 8]
lea edx, [edx + 4*edx]
shl edx, 6
mov byte ptr [edx + ecx + 40960], al这段代码比我们三十年前精心设计、针对当时处理器优化的版本要精简得多。处理器在这三十年间经历了巨大进化 —— 新增了诸多先进特性与指令集(本章稍后将详述这些新指令),而编译器优化例程对 320 这个“友好数字”的乘法处理方式尤其令人叹服。
从 Turbo C++、Watcom C++ 等早期版本起步,C++ 编译器已发展为极其复杂的系统。它们不再只是简单地将人类可读代码转译为机器码,而是能通过函数内联、循环展开、常量折叠、死代码消除等高级优化技术,以及跨模块/程序的全局优化策略,显著提升性能与内存使用效率。GCC、Clang 和 MSVC 都充分利用现代硬件特性(如向量化与并行指令),针对特定处理器生成高效机器码(下节实例将生动展示这些优化效果)。
不过,在进入正题前,请允许我再分享一个三十年前的案例。本章副标题本意是指:不应采用更底层的编码方式 —— 但此刻我们要自豪地自我反驳:在某些情况下,你确实需要突破汇编层面向下探索。
熟悉图形编程的读者应该了解双缓冲技术:后备缓冲区(与屏幕等大的离屏内存区域)先完成所有图形渲染,再整块复制至屏幕显示。历史上加拿大开发者 Tom Duff 发明的 "Duff 装置"(一种循环展开技术)完美解决了这个问题。
不过我们要展示的是当年自诩“高度优化”的后备缓冲区复制代码:
void flip(unsigned int source, unsigned int dest) {
asm {
push ds // Save the current value of the DS register
mov ax, dest // Load the destination address into AX
mov es, ax // Copy the value from AX into the ES
mov ax, source // Load the source address into AX
mov ds, ax // Copy the value in AX into the DS
xor si, si // Zero out the SI (source index) register
xor di, di // Zero out the DI (destination index)
mov cx, 64000 // Load 64000 into the CX register
// (this is the number of bytes to copy)
rep movsb // Run the`movsb` instruction 64000
// times (movsb copies bytes from DS:SI to ES:DI)
pop ds // Restore the original value of the DS
}
}这段代码的精髓在于 rep movsb 指令 —— 它会按照 CX 寄存器指定的次数(64,000次)重复执行字节复制(movsb)。这个“魔法数字”的由来我们都清楚:64,000 = 320 × 200,正好对应屏幕分辨率下的总像素数。
在当时的硬件环境下,这段代码堪称完美。但若使用至少 80386 这样的高端处理器(相比纯16位的 80286,这是英特尔首款32位 x86 处理器),我们还能进一步优化:不再复制 64,000 字节,而是改用 rep movsd 指令处理 16,000 个双字(32位)。因为:1字节=8位,2字节=1字(16位),2字=1双字(32位) —— 这正是新处理器原生支持的操作位宽。新引入的 movsd 指令单次就能拷贝 4 字节,理论上比旧代码快 4 倍。
但本书开头提到的 Turbo C++ Lite 编译器有个致命缺陷:它只能为 80286 及以下处理器生成代码,被迫使用 16 位寄存器和低效的寄存器操作。于是,在 C++ 代码中出现了最底层的 hack —— 直接在代码里以十六进制形式硬编码 rep movsd 指令的机器码:
xor di,di
mov cx,16000
db 0xF3,0x66,0xA5 //rep movsd
pop ds还有什么比在生产代码中看到这种硬编码机器指令更“简单粗暴”又令人泪目的呢?虽然我们的编译器还停留在石器时代(就像你现在读的这半章内容一样),无法为 80386 生成原生代码,但我们依然能写出在新型处理器上最优运行的代码 —— 不过请不要真的在现代项目中这么做。
8.1.1 关于往事的注记
如今,你或许会问:在 2025 年这个 AI 驱动开发工具大行其道、低代码/无代码平台蓬勃兴起、各种语法翻新但功能雷同的 JavaScript 模块层出不穷的时代,我们为何还要讨论汇编语言?
尽管这些确实是当今 IT 界最喧嚣的趋势,但汇编语言仍未过时。它或许不像万众追捧的 Rust 那样风光(如果计划顺利,Alex 将在后续章节探讨 Rust),但在某些关键领域,汇编仍是不可替代的刚需。
以下是一些仍需汇编技术的核心场景:
- 嵌入式系统:微控制器和物联网设备常需要汇编来实现高效底层编程 —— 这些微型设备的算力捉襟见肘,每一个比特都弥足珍贵。
- 操作系统开发:引导程序与内核关键组件依赖汇编进行硬件初始化与管理。要进入这类开发,要么供职于大企业,要么参与开源项目(如 Linux 生态已基本覆盖该领域)。
- 高性能计算:科学计算与定制硬件(如 FPGA)中,汇编用于优化性能关键代码。当然,前提是能找到愿意为此付费的雇主。
- 安全与逆向工程:二进制分析与漏洞利用往往离不开汇编知识。遗憾的是,这既是汇编领域最赚钱的方向,也是最现实的入行途径。
- 固件开发:BIOS、UEFI 和底层设备驱动程序普遍使用汇编实现硬件交互。该领域主要由大企业主导,但也存在 coreboot、libreboot 等开源项目可供探索。
- 遗留系统维护:复古计算与老旧系统维护常需汇编技能,堪称痛苦与乐趣并存的独特体验。
- 专用硬件:数字信号处理器(DSP)和定制 CPU 架构可能需要汇编实现高效的专用处理。
请别急于否定汇编语言 —— 只要计算机存在,它就永不褪色。对特定领域感兴趣的人自会珍视它的价值,其他人尽可继续使用标准 C++。