4.2. 企鹅(Linux)农场
当 Linux 加载并准备执行一个应用程序时(假设这是一个可执行文件,而非 shell 脚本等其他类型),通常会通过一对 fork() 和 execve() 系统调用来启动这个过程。
这两个系统调用的作用:首先,fork() 用于复制当前进程,生成一个子进程;随后,execve() 将该子进程的映像替换为新的进程映像,即执行的应用程序。这种方法提供了一种灵活且高效的方式来启动新任务。
Mark Mitchell、Jeffrey Oldham 和 Alex Samuel 在他们的著作《Advanced Linux Programming》中对这些系统调用进行了详尽的解释。此外,网络上也有丰富的资源可供进一步了解这一主题。因此,对于有兴趣深入了解的朋友来说,这些资料都是极好的信息来源。
接下来,让我们继续探讨可执行文件的加载过程。在一系列调用后,execve() 系统调用将跳出用户空间限制,进入 Linux 内核,并创建一个 linux_binprm 结构体https://github.com/torvalds/linux/blob/master/include/linux/binfmts.h。根据文档描述,此结构体用于二进制文件的加载,它包含了加载和执行一个二进制文件所需的所有关键信息。
如果有充裕的时间,并且手中有一杯热茶,同时对 C 语言的复杂机制有较深的理解。可以尝试阅读 Linux 内核源码树中的 do_execveat_common 函数实现,以探索其背后的工作原理https://github.com/torvalds/linux/blob/master/fs/exec.c。
随后,内核需要确定可执行文件的格式。在 Linux 环境下,最常见的可执行文件格式是 ELF(Executable and Linkable Format,即可执行与可链接格式)。
所有字段都在官方标准文档中有详细描述https://refspecs.linuxfoundation.org/elf/elf.pdf,在此我们仅对我们当前使用场景相关的字段做一个简要总结:
| 字段名 | 偏移 | 描述 |
|---|---|---|
| MAGIC | 0x00 | 表示文件是ELF文件的魔数(“ELF”在ASCII和0x7F中表示) |
| CLASS | 0x04 | ELF文件的类(32位或64位) |
| e_type | 0x10 | 标识目标文件类型(例如,可执行文件、共享对象等) |
| e_machine | 0x12 | 指定为其编译文件的架构 |
| e_entry | 0x18 | 虚拟地址,系统首先将控制权转移到该地址,然后开始进程 |
请记住这张表格,我们稍后还会再次引用它。现在,继续深入程序的加载过程。
一旦内核确认了可执行文件的格式是 ELF(Executable and Linkable Format),它就会开始解析 ELF 文件头部,以了解整个程序的结构布局。这一步至关重要,它决定了后续如何将程序映射到内存中并准备执行。
在这个阶段,通常会执行以下关键操作:
- 内存分配:内核为新进程分配内存。这包括设置进程的地址空间,地址空间由不同的段(segment)组成,例如文本段(代码)、数据段、堆(heap)和栈(stack)。
- 节区映射:内核将可执行文件中的各个节区(section)或段(segment)映射到进程的地址空间中。例如,文本段会映射为只读,以防止意外修改;而数据段则被映射为可读写,以便运行时更新全局变量。
- 动态链接:如果该可执行文件依赖共享库(shared libraries),则会调用动态链接器/加载器(ld.so)来加载必要的共享库并解析符号引用。动态链接器还会将这些库映射到进程的地址空间中。
这些底层操作都发生在 Linux 内核的核心部分。如果你对操作系统底层机制感兴趣,强烈建议阅读相关源码 —— 或许会从中发现许多令人着迷的实现细节。
一旦这些复杂的低层操作顺利完成,内核就会为该进程构建初始的用户态环境栈(stack)。这个栈中包含了程序启动所需的关键信息,主要包括:
- 参数向量(argv):命令行参数数组,即用户传入的启动参数。
- 环境变量(envp):当前进程的环境变量列表,通常用于配置运行时行为。
- 辅助向量(auxv):一组附加信息,包括但不限于系统页面大小、ELF 程序入口点、线程 TLS 配置等,供运行时库或动态链接器使用。
所有这些准备工作,都在内核源文件 binfmt_elf.c 中的一个关键函数中完成:
static int create_elf_tables(struct linux_binprm *bprm,
const struct elfhdr *exec, unsigned long interp_load_addr,
unsigned long e_entry,unsigned long phdr_addr) { ... }当运行时环境准备好之后,内核会设置 CPU 的指令指针(Instruction Pointer),使其指向程序的入口点(该地址记录在 ELF 头部的 e_entry 字段中)。同时,其他寄存器也被正确初始化,以确保程序能顺利执行。最后,内核将 CPU 切换回用户模式,并将控制权转移给应用程序的入口地址。
在 Linux 系统中,这一控制权的切换主要通过 start_thread() 函数完成,该函数是架构相关的。以 x86 架构为例,在撰写本文时,该函数定义位于 arch/x86/include/asm/processor.h,并在 arch/x86/kernel/process_64.c 中具体实现。
从这一刻起,程序正式开始执行。这也是最有趣的部分 —— 至少从 C++ 开发者的角度来看。
首先执行的是程序的初始化代码,这部分通常属于 C 运行时库(CRT),最常见的入口函数是 _start(),而非我们熟悉的 main()。ELF 文件头中的 e_entry 字段指定了程序执行的起始偏移地址,而在标准 GNU 工具链编译的程序中,通常指向 _start() 函数的位置。
这段代码的主要职责是初始化运行时环境,并最终调用我们自己编写的 main() 函数。从那时起,程序便按照我们所设计的逻辑开始运行。
那么,来看看这个初始化代码到底长什么样。我们将借助一个强大的逆向分析工具 Ghidra,它可以用来剖析 Linux 可执行文件并研究其内部结构。对于这个看似“空”的应用程序,Ghidra 提供了如下视图:
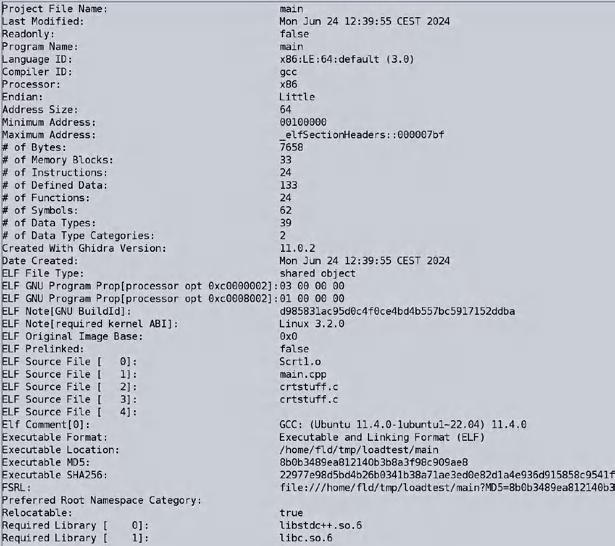 图 4.1 —— 应用程序的结构
图 4.1 —— 应用程序的结构当我们查看 ELF 文件中的源码信息时,可以看到我们最初编写的 main.cpp 文件。然而,除了它之外,还有一些我们并不熟悉的文件,例如 crtstuff.c。该文件属于 libgcc,可以在 libgcc 的代码仓库https://github.com/gcc-mirror/gcc/blob/master/libgcc/crtstuff.c中找到,在文件顶部写着如下注释:
/* Specialized bits of code needed to support construction and destruction of file-scope objects in C++ code.这段注释已经很好地解释了其作用 —— 它负责支持 C++ 中文件作用域对象(即全局或静态对象)的构造与析构过程。至此,其中一个谜团已经解开。
不过还有一个问题仍然存在:Scrt1.o 是什么?
要理解这一点,我们需要先了解“固定地址可执行文件”(Fixed-Address Executables)和“位置无关可执行文件”(Position-Independent Executables,简称 PIE)之间的区别。
固定地址可执行文件是指被编译为在特定内存地址加载的程序。其结构简单,但缺乏灵活性和安全性,攻击者可以轻易预测其内存布局,从而发起针对性攻击。这类可执行文件常见于嵌入式系统以及一些旧平台(如 MS-DOS),后者甚至要求 .com 程序必须从特定偏移地址加载。
而 PIE(Position-Independent Executable) 则是一种更现代、更安全的做法。这种类型的可执行文件可编译和链接为可以在任意内存地址加载。它使得地址空间布局随机化(ASLR)成为可能 —— 这是一种重要的安全机制,通过每次运行时将程序加载到不同的内存地址,大大增加了攻击者利用漏洞的难度。
在编译程序时,我们可以使用一系列标志来控制生成代码的方式,其中 -fPIE、-pie 和 -fPIC 这些标志尤其关键,并影响着程序如何处理内存地址依赖关系:
- -fPIE(position-independent executable): 告诉编译器生成适用于可执行文件的位置无关代码。这通常是构建 PIE 可执行文件的第一步,并且这对于创建支持 ASLR 的可执行文件非常有用。
- -pie(链接阶段使用的 PIE 标志): 在链接阶段使用,指示链接器生成一个位置无关的可执行文件。这样最终的可执行文件就可以被加载到任意内存地址,从而支持 ASLR。通常与 -fPIE 配合使用,以确保整个程序都是位置无关的。
- -fPIC(position-independent code): 用于生成共享库的位置无关代码。由于共享库可能会被多个进程同时加载,并且每个进程的加载地址不同,因此这种特性对共享库至关重要。
现在已经了解了这些重要概念,回到最初的问题:二进制文件中的另一个未解之谜 —— Scrt1.o。
还记得 _start() 函数吗?你并没有自己编写它,但它确实存在于程序中。那它是从哪来的呢?答案是:它来自 Scrt1.o 这个特殊的对象文件。crtX.o 系列文件是一组 CRT(C RunTime)启动文件,用于初始化程序运行环境。这些文件有多种变体,有些以 S 开头,有些则没有。对于当前的例子来说,Scrt1.o 的存在表明应用程序是一个 PIE 可执行文件。
下面是一些常见的 CRT 相关文件及其作用简介:
- crt0.o, crt1.o 等: 这些文件包含 _start 符号,是程序的真正入口点。不同 libc 实现之间命名约定可能略有差异。
- crti.o: 为 .init 和 .fini 段定义函数前序(prologue),并触发链接器生成的动态标签(如 DT_INIT 和 DT_FINI)。我们稍后会详细讨论这些概念。
- Scrt1.o, gcrt1.o, Mcrt1.o: 这些是 crt1.o 的变种,用于不同场景,例如生成 PIE 或包含性能分析支持。
- crtbegin.o, crtbeginS.o, crtbeginT.o: 这些文件由 GCC 使用,用于定位构造函数(constructors)。其中 crtbeginS.o 用于共享对象/PIE,crtbeginT.o 用于静态可执行文件。
- crtend.o, crtendS.o: 类似于 crtbegin.o,它们用于定位析构函数(destructors),其中 crtendS.o 用于共享对象/PIE。
在揭开可执行文件结构的神秘面纱之后,还有一个关键部分值得关注:ELF 文件中的 .init_array 节区。该节区用于存储一组函数指针,这些函数会在程序启动时由操作系统的运行时加载器自动调用。这些函数通常被称为“初始化函数”,会在 main() 函数之前调用,负责初始化全局数据。
对于我们这个合成示例程序,当 Ghidra 分析 .init_array 节区时,会呈现出如下内容:
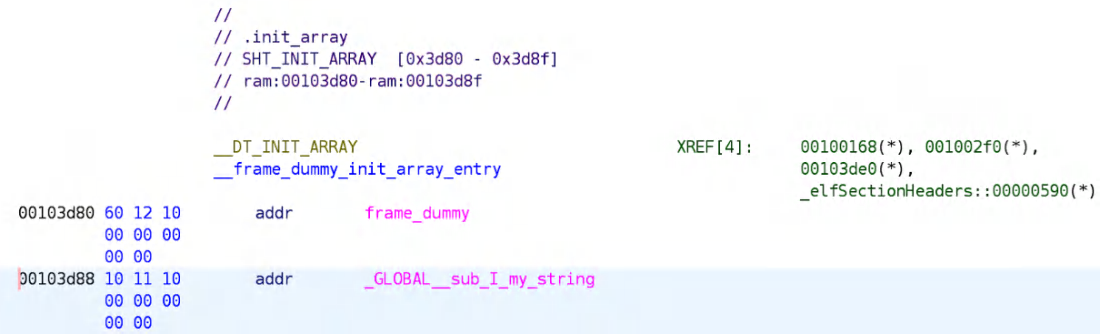 图 4.2 —— 用于全局变量的 .init_array 节区
图 4.2 —— 用于全局变量的 .init_array 节区这里有两个函数 —— 一个空函数(dummy)和一个名为 _GLOBAL__sub_I_my_string 的函数。这是一个颇有趣的名字选择。接下来,利用工具将汇编代码转换为类 C 代码的功能,来看看它具体做了什么:
 图4.3 —— 如何根据Ghidra创建全局对象
图4.3 —— 如何根据Ghidra创建全局对象很有趣,不是吗?这正是在全局命名空间中期望发生的行为。
在这里,创建了两个对象my_a 和 my_other_a ,调用了它们的构造函数,并且类 A 的析构函数也注册到了 __cxa_atexit 中。尽管这一切看起来再自然不过,但其背后的机制却颇为精妙。
从这段略显复杂的反汇编代码中,你可能会注意到:构造函数似乎接收了一个“隐藏”的参数,用于指定它正在构造的对象。没错,这个参数就是 this 指针。它是 C++ 类方法的一个隐式参数,由编译器自动添加,无需程序员显式声明。也正是通过它,才能访问当前对象的成员变量和方法。
顾名思义,__cxa_atexit 函数的作用与 atexit 类似 —— 用于注册程序退出时需要调用的清理函数。只不过 __cxa_atexit 是 C++ 运行时系统内部使用的扩展版本,专门用于管理 C++ 对象的析构。不需要也不应该手动处理它,它属于底层运行时机制的一部分,通常由编译器和运行时库自动管理。
现在我们已经明白了这里发生了什么,是时候回到之前提到的另一个话题了:那个神秘而又至关重要的 _start() 函数。
如前所述,这个函数是程序执行的真正起点。它负责完成一系列初始化工作,并最终调用 main() 函数。
据 Ghidra 的反汇编分析,该函数确实存在于我们的 ELF 可执行文件中。按照 ELF 文件格式规范,它的入口地址被记录在 ELF 头部的 e_entry 字段中,也就是程序开始执行时 CPU 指令指针(如 x86 上的 RIP)所指向的位置。
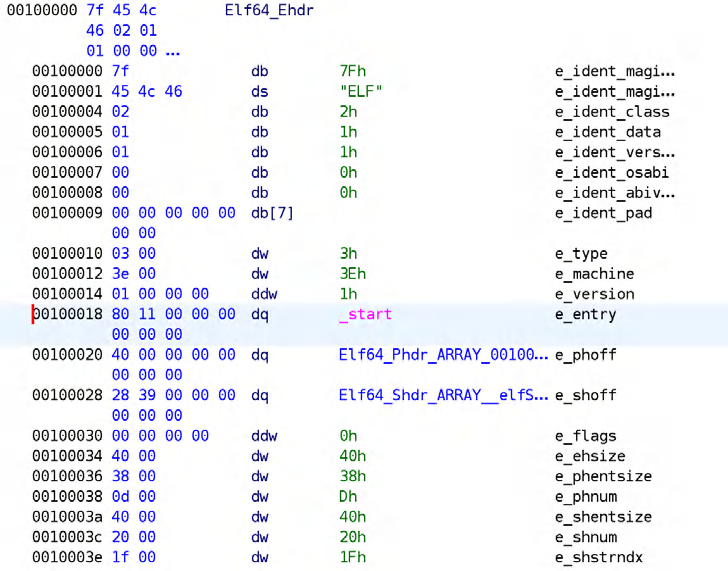 图4.4 —— 根据Ghidra的ELF头
图4.4 —— 根据Ghidra的ELF头现在,在借助 Ghidra 进行了一番反汇编“魔法”操作之后,_start() 函数的真面目浮出水面,如下图所示:
 图4.5 —— _start例程函数,反汇编并转换为C伪代码
图4.5 —— _start例程函数,反汇编并转换为C伪代码这个看起来吓人的 __libc_start_main 函数其实并没有它表面看起来那么可怕。它负责加载我们的 main() 函数,并处理操作系统所提供的参数。这个函数是 glibc 的一部分,和其他开源软件一样,也可以免费获取git clone git://sourceware.org/git/glibc.git,方便我们研究其内部机制。
在这个阶段,随着 __libc_start_main 的执行完成,我们终于进入了真正的 main 函数 —— 也就是预期程序开始运行的地方。
这些底层细节不仅帮助我们建立起对程序执行流程的全面理解,也为后续的性能优化与调试分析打开了新的思路。掌握 ELF 文件格式、链接器行为以及启动过程的工作原理,使我们能够通过特定的链接器选项来优化程序结构,深入理解动态链接的复杂机制,并在调试过程中追踪初始化流程,识别并解决与启动相关的潜在问题。
4.2.1 好戏才刚刚开始!
既然已经走到这里,正坐在 Linux 机器前,那就不再浪费时间,直接深入探讨一下这个伟大操作系统所配备的一些编译器内部机制吧。例如,更仔细地研究 ELF 文件中的 .init_array 节区。
如前所述,.init_array 的作用是在 main() 函数执行之前调用一系列初始化函数。这些函数通常用于构造全局对象、注册析构函数,以及其他与程序启动相关的准备工作。
然而,在继续这场穿越“泥泞沼泽”的旅程之前,请允许我发出一个警告:接下来要讨论的内容并不适合胆小或保守的 C++ 开发者。事实上,这些机制本身就不是标准 C++ 的一部分 —— 其属于编译器的扩展功能。如果你希望深入了解这方面的内容,请参考第 2 章中关于 C++ 标准性的相关讨论。
如果愿意接受这些“非正统”的编译器扩展思想,并从中挖掘其背后的强大能力,那么请继续阅读。
GCC(以及 Clang)提供了一个非常实用的扩展机制,允许开发者定义在 main() 执行之前自动运行的函数。这些函数称为“构造函数”(constructors),通过使用特定的属性声明来实现:
__attribute__((constructor)) void welcome() {
printf("constructor fun");
}如果将这段特定的代码添加到合成应用程序中,可以得到以下输出:
constructor fun
A::A : Hello string
A::A : Go away string
Hello, World, Hello string, Go away string
A::~A : Go away string
A::~A : Hello string构造函数会在全局对象初始化代码之前执行。 如果我们打开我们钟爱的“黑桃九”可执行文件,并查看 .init_array 节区,将会看到如下内容:
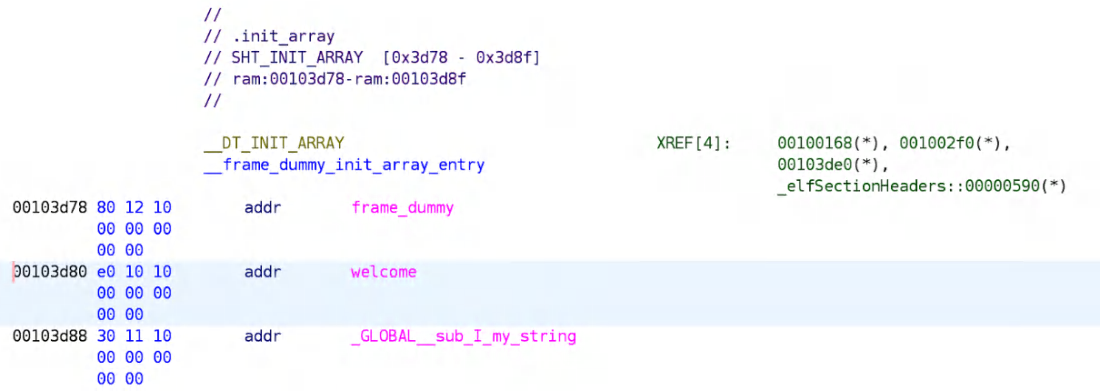 图 4.6 —— 包含构造函数的 .init_array 节区
图 4.6 —— 包含构造函数的 .init_array 节区有了以上这些知识,我们现在掌握了两种在 main() 函数之前执行代码的方式:构造函数函数(constructor functions) 和 全局变量的构造初始化。
然而,也正是在这个层面上,我们开始触及一个臭名昭著的问题 —— “静态初始化顺序灾难”(Static Initialization Order Fiasco)。这是一个在 C++ 社区中被反复讨论的经典话题。
这个问题的核心在于:不同编译单元(translation unit)之间的静态或全局对象的初始化顺序是未定义的。所以无法确定一个编译单元中的全局对象,会在另一个编译单元中的全局对象之前还是之后完成初始化。这种不确定性可能会导致微妙而难以调试的运行时错误。
虽然存在一些技术手段可以缓解这一问题(如使用局部静态变量、Singleton 模式、惰性初始化等),但我们建议:尽可能避免依赖跨编译单元的静态或全局对象初始化机制。它们不仅难以维护,而且容易引发潜在的稳定性问题。
下面的例子将展示为什么这种情况可能带来严重风险。我们将通过几个简短的源文件来模拟现实开发中常见的场景,使用的仍然是合成代码,但其行为足以说明问题的本质:
#ifndef A_H
#define A_H
class C;
extern C a_c;
#endif#ifndef B_H
#define B_H
class C;
extern C b_c;
#endif#ifndef C_H
#define C_H
#include <cstring>
#include <cstdio>
struct C {
C(const char* p_c) : m_c(nullptr) {
m_c = new char[32];
strcpy(m_c, p_c);
printf("C::C :
}
~C() {
printf("C::~C :
delete[] m_c;
}
private:
char* m_c;
};
#endif#include "C.h"
C a_c("A");#include "C.h"
C b_c("B");int main()
{
}这段代码并不复杂 —— 它只是定义了一个用于输出调试信息的诊断类 C,以及一些独立的 C++ 源文件,这些文件中创建了该诊断类的实例对象。
这些文件一般使用 GCC 编译。接下来,我们使用 GCC 对它们进行编译,并运行生成的可执行文件:
> $ g++ main.cpp a.cpp b.cpp -o test
> $ ./test
C::C : A
C::C : B
C::~C : B
C::~C : A看起来一切都很平常 —— 成功编译并生成了一个可执行文件,它也表现得一如预期:在特定对象创建和销毁时打印相应的信息。
然而,一个值得思考的问题出现了:如果以不同的顺序指定源文件进行编译,会发生什么?
> $ g++ main.cpp b.cpp a.cpp -o test
> $ ./test
C::C : B
C::C : A
C::~C : A
C::~C : B这确实令人意外。现在我们看到,b.cpp 中定义的全局对象 b_c 竟然在 a.cpp 中的 a_c 之前完成了构造。
试想这样一个灾难性的场景:程序由多个全局对象组成,而其中某个对象的初始化逻辑依赖于另一个全局对象已经正确构造。在这种情况下,未定义的初始化顺序可能会导致严重的行为不一致,甚至引发运行时错误 —— 这就是“静态初始化顺序灾难”。
幸运的是,在 Linux 下的现代编译器生态中,并非毫无办法。GCC 和 Clang 都提供了一个非常实用的扩展功能,让我们能够对全局对象的初始化顺序进行精细控制,从而规避上述问题。
这个扩展就是:__attribute__((init_priority(XXX)))。
通过为全局或命名空间作用域的对象指定 init_priority 属性,可以明确其在初始化阶段的执行顺序。该属性接受一个介于 101 到 65535(包含)之间的整数值作为优先级标识。数值越小,优先级越高 —— 具有较低 init_priority 值的对象会比数值高的对象更早完成初始化。
掌握这一机制后,就可以回过头来修改之前的合成示例代码,让它们显式地使用这个扩展,从而确保初始化顺序符合预期:
#include "C.h"
__attribute__((init_priority(1000))) C a_c("A");#include "C.h"
__attribute__((init_priority(1001))) C b_c("B");现在,无论将 a.cpp 和 b.cpp 引入编译器的顺序如何,结果相同:
> $ g++ main.cpp a.cpp b.cpp -o test
> $ ./test
C::C : A
C::C : B
C::~C : B
C::~C : A
> $ g++ main.cpp b.cpp a.cpp -o test
> $ ./test
C::C : A
C::C : B
C::~C : B
C::~C : A现在,让我们回到最初的合成应用程序 —— 一个在同一个翻译单元中创建全局对象的简单程序。同时,还将引入“构造函数函数”(constructor functions)的概念。
如果为其中一个全局对象指定 init_priority 初始化优先级,那么各个初始化阶段的执行顺序会发生什么变化。
通过这个实验,可以更清楚地理解编译器如何处理具有指定初始化优先级的对象,以及它与普通构造函数函数和同一翻译单元内全局对象之间的初始化顺序关系。
__attribute__((init_priority(1000)))
A my_other_a(my_other_string);令人惊讶的是,输出如下所示:
A::A : Go away string
constructor fun
A::A : Hello string
Hello, World, Hello string, Go away string
A::~A : Hello string
A::~A : Go away string为了更深入地理解这一现象背后的机制,并揭示其发生的原因,使用逆向分析工具对编译后的二进制文件进行了进一步分析。结果显示,我们的观察完全正确,如下图所示:
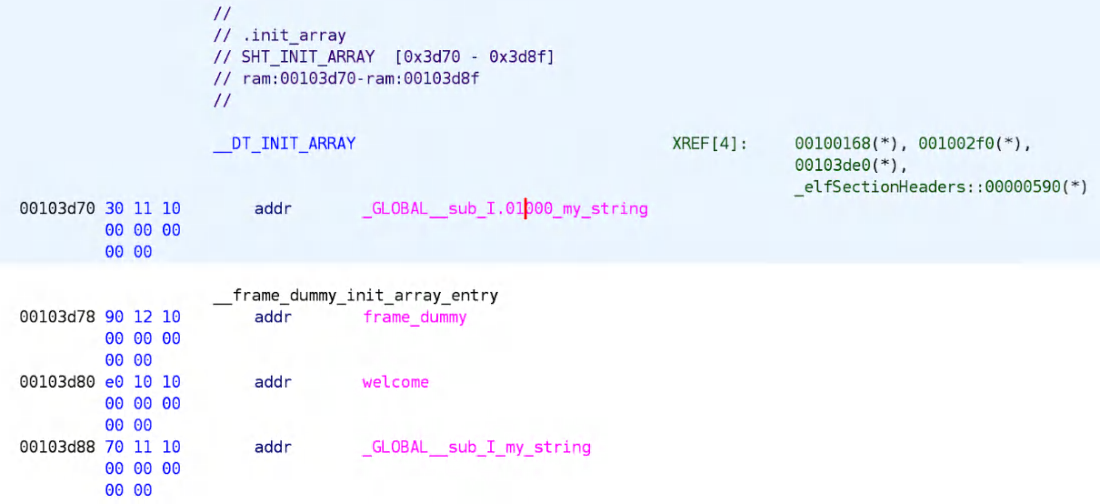 图 4.7 —— 根据gcc的.init_array节指定初始化优先级
图 4.7 —— 根据gcc的.init_array节指定初始化优先级正如所见,程序输出与预期一致。这是因为 .init_array 节中新增了一个条目 —— 一个在构造函数和标准全局对象初始化代码之前执行的函数。
不难猜测,这个新函数的名称中包含了已设置的初始化优先级数值。然而,令人困惑的是,GCC 依然选择将变量名 my_string 作为该函数符号的一部分进行保留。这似乎是 GCC 特有的行为,因为在使用 Clang 编译相同代码时,生成的 .init_array 部分则呈现出另一种形式:
图 4.8 —— Clang的不同.init_array节,用于相同的init优先级GCC 和 Clang 在处理这类关键初始化机制时竟然存在如此明显的差异,是一件非常有趣的事情。不过,在深入研究两者的源码实现之前,这种行为背后的确切原因仍将是一个未解之谜。
4.2.2 库是{孕育思想
意外行为的温床}到目前为止,我们一直是这个应用程序的“快乐父母”。现在,是时候让“爱情结晶”长大成人,并“成家立业”了……换句话说,为了遵循良好的软件工程实践,并迈向更高级的编程结构,我们将从之前的合成代码中提取出一些非常有用的功能,将它们封装成一个合成库,并为它取一个响亮的名字:synth。
呃……抱歉,准确来说是:libsynth。
鉴于本章的重点仍然是剖析 main() 函数之前执行的那些初始化代码(1),并且依然愉快地支持使用 GCC(以及 Clang)提供的扩展机制(2),那么接下来将看到:当以一种“非标准但强大”的方式把这些元素结合在一起时,会发生什么 —— 可以把它理解为代码与数据之间的一次“结合”。
我们将继续使用上一阶段的第二个合成示例。在这个示例中,a.cpp 和 b.cpp 保持不变,并保留我们之前设定好的初始化顺序。创建一个新的 main.cpp 文件来调用这个库,并介绍该库本身的源代码结构。
库将由以下代码构建而成:
#include "C.h"
#include <cstdio>
__attribute__((init_priority(2000))) C synth_c("synth");
__attribute__((constructor)) void welcome_library() {
printf("welcome to the library");
}
void print_synth() {
printf("print_synth:
}#ifndef SYNTH_H
#define SYNTH_H
void print_synth();
#endif除了定义一个类型为 C(如头文件 C.h 中所定义)且初始化优先级为 2000 的全局对象 synth_c 之外,还定义了一个名为 welcome_library 的函数,并使用 __attribute__((constructor)) 标记它,确保该函数在 main() 之前运行,并输出 “welcome to the library”。
此外,我们还实现了 print_synth 函数,它负责打印一条信息,显示通过调用 synth_c.get() 所获取的值。至于 C.h 头文件,则与前文中所描述的一致 —— 定义了类 C 及其所有必要的构造函数、方法和成员变量,以支持全局对象的正确初始化和使用。
为了在实际项目中使用这个库,需要为其构建一套底层基础设施。这包括上述提到的两个源文件(synth.cpp 和 C.cpp),以及一个新的应用程序,用于测试并演示该库所提供的功能。
同时,为了保持实验的一致性和可追踪性,我们希望对主程序文件进行适当的修改,使其能够调用新创建的库功能,但又不丢弃此前用于验证初始化顺序的测试源文件(即 a.cpp 和 b.cpp)。
因此,我们的应用程序将包含前面提到的a.cpp和b.cpp文件,以及新的main.cpp文件:
#include "synth.h"
#include "C.h"
__attribute__((constructor)) void welcome_main() {
printf("welcome to the main");
}
C main_c("main") ;
int main() {
print_synth();
return 0;
}为了使一切正常工作,我们需要链接这些项,并将其变成一个可工作的应用程序:
> $ g++ -c -o synth.o synth.cpp
> $ ar rcs libsynth.a synth.o
> $ g++ -o main main.cpp a.cpp b.cpp -L. -lsynth在这一阶段,我们已经成功构建了一个静态库 libsynth.a,并将主应用程序与其进行链接,从而将库中的所有功能完整地整合进最终的可执行文件中。
请注意,这里并不存在一个单独的 c.cpp 文件。为了保持结构尽可能简洁,我们将类 C 的所有实现直接写在了头文件中。虽然这种方式在更大的项目中并不是一种推荐的做法 —— 因为类中任何一个函数的实现发生微小改动,都会导致所有包含该头文件的源文件都需要重新编译。
由于本阶段的重点仍然是观察各类构造代码和初始化函数的执行顺序,在运行生成的应用程序后,得到了如下输出:
> $ ./main
C::C : A
C::C : B
C::C : synth
welcome to the main
C::C : main
welcome to the library
print_synth: synth
C::~C : main
C::~C : synth
C::~C : B
C::~C : A为了更深入地探究这个新构建的可执行文件的内部结构,我们再次使用我们钟爱的逆向分析工具 Ghidra 打开它,并将目光聚焦在.init_array节区。
通过快速浏览可以发现,程序运行时构造函数的调用顺序,与 .init_array 节区中函数指针的排列顺序完全一致:
 图 4.9 —— .init_array节用于不同文件中的不同初始化优先级
图 4.9 —— .init_array节用于不同文件中的不同初始化优先级在上图中,_GLOBAL__sub_I_welcome_main 是负责在 main.cpp 中创建全局对象的函数 —— 也就是那行 C main_c("main");。有趣的是!这一观察结果进一步验证了我们的判断:即便是静态库中的全局对象,其初始化顺序机制依然按照预期正常工作。
但我们探索的脚步并未就此停止。接下来,如果尝试将这个库构建为一个共享库(Shared Library),又会发生什么?
这并不是一个复杂的过程。在清除之前生成的文件(如 synth.o、libsynth.a 和 main)以确保构建环境干净之后,我们可以运行以下命令来构建一个共享库:
> $ g++ -fPIC -c -o synth.o synth.cpp
> $ g++ -shared -o libsynth.so synth.o
> $ g++ -pie -o main main.cpp a.cpp b.cpp -L. -lsynth正如我们在本章开头所讨论的那样,构建共享库以及使用它的应用程序其实是一个非常直接的过程。现在,已经成功创建了共享库 libsynth.so 以及一个链接并使用它的应用程序。
有了这些构建成果,我们可以借助 Ghidra 来观察应用程序结构发生的一些有趣变化:
 图 4.10 —— 作为依赖项的 synth 库,如 Ghidra 所示
图 4.10 —— 作为依赖项的 synth 库,如 Ghidra 所示如上图所示,Ghidra 清晰地展示了我们刚刚创建的 libsynth.so 共享库已被应用程序正确链接为一个动态依赖项。
接下来,让我们聚焦于ELF的.init\_array节区:
 图 4.11 —— .init\_array部分没有提到 libsynth
图 4.11 —— .init\_array部分没有提到 libsynth在 .init\_array 节区中,并没有任何与 libsynth 相关的构造函数或全局对象初始化的引用。这并不令人意外 —— 毕竟是一个共享库。尽管如此,我们仍然可以通过 Ghidra 或运行时工具确认应用程序确实已正确链接到该库,并且能够在运行时调用其中的函数。
> $ LD_LIBRARY_PATH=. ldd ./main
linux-vdso.so.1 (0x00007fff17387000)
libsynth.so => ./libsynth.so (0x00007ea84ee45000)
libstdc++.so.6 => /lib/x86_64-linux-gnu/libstdc++.so.6请注意,必须显式地指定 LD_LIBRARY_PATH=.,以便系统能够找到该库(同时还省略了部分不必要的输出行以保持内容清晰)。
此时,我们好奇地想知道在执行该应用程序时会发生什么:
> $ LD_LIBRARY_PATH=. ./main
C::C : synth
welcome to the library
C::C : A
C::C : B
welcome to the main
C::C : main
print_synth: synth
C::~C : main
C::~C : B
C::~C : A
C::~C : synth根据我们在单一应用程序测试中设定的预期,具有指定优先级的全局对象首先在库中被创建。接着,库中的构造函数被调用。如果库中还存在其他未指定优先级的全局对象,它们将在这些带有优先级的对象之后被创建。随后,主应用程序中带有优先级的全局对象开始创建,最后才是主应用程序的构造函数被调用。这一切都发生在 main() 函数执行之前 —— 甚至在 main() 函数有机会“说句话”之前就已经完成。
几乎完全如我们所预期的那样。然而,在这些构造函数扩展机制中,仍有一个我目前尚未找到解决办法的“黑暗角落”。具体来说,如果让 a.cpp 和 b.cpp 包含以下代码,会发生什么呢?
__attribute__((constructor)) void welcome_a() {
printf("welcome to the 'a' file");
}
__attribute__((constructor)) void welcome_b() {
printf("welcome to the 'b' file");
}这段“颇具风险”的代码又为我们的可执行文件随意添加了两个构造函数函数,现在我们一共拥有了三个构造函数。
如果你希望这些构造函数的执行顺序也是可预测且可控的,那么你就需要使用 GCC(以及 Clang)提供的扩展语法来明确指定它们的优先级。例如:__attribute__((constructor(205))) void welcome_b()。通过这种方式,可以确保这些构造函数按照你期望的顺序依次执行,从而有效避免陷入“全局构造函数调用顺序灾难”。
此外,在共享库是通过 dlopen() 动态加载的情况下,其行为也完全符合预期:构造函数和全局对象的初始化逻辑会在库被加载时自动触发执行 —— 即当程序运行到调用 dlopen() 的那一时刻。此时,控制流会跳转至该库的初始化代码并完成必要的设置工作。
同样地,当你调用 dlclose() 来卸载该共享库时,如果存在对应的析构函数,它们也将正确调用,并完成清理操作。
4.2.3 最后的话
本章深入探讨了在 main() 函数之前执行的代码,但同样值得关注的是在 main() 函数之后执行的代码。不过,这个话题将在另一本书或不同的章节中详细展开讨论。
为了满足你的好奇心,这里先透露一个小提示:正如存在构造函数(constructor functions),也存在析构函数(destructor functions)。这些析构函数并不等同于 C++ 中类成员的析构函数,而是通过如下方式定义的全局函数: __attribute__((destructor))) 。
结合标准库中的程序退出机制,你会发现这一过程比程序启动更加复杂且有趣。你需要考虑更多的情况,例如通过 std::atexit() 或 std::quick_exit() 注册的函数,以及异常终止程序的情形。例如:
如果一个异常在析构函数中抛出,或者我们调用了 std::terminate() 或 std::abort(); GGCC 和 Clang 的文档对这些偏离标准的行为提供了许多有趣的“冒险”,揭示了它们在不同场景下的行为差异。
任何一本优秀的 C++ 书籍都会对标准的终止流程提供全面的概述,因此建议你查阅这些资料以获得深入理解。将这两部分内容结合起来,可以为提供关于应用程序如何启动与退出的最完整视角。
然而,在 Packt 出版社因为我们的篇幅严重超出原定计划而对我们进行严厉批评之前,需要将暂时把注意力转向其他方向。原本约定本章为 16 页,但我们现在已经写到了第 22 页,却只覆盖了原定主题的一半。
尽管如此,我们已经奠定了坚实的基础,掌握了从程序启动到退出过程中各个关键环节的工作原理。希望这些内容能激发你进一步探索相关主题的兴趣,并帮助你在实际开发中更好地管理程序的生命周期。