8.3. 初级方案(及其缺陷)
现在已经有了方案,可以开始实现内存泄漏检测器的初始版本了。这个实现虽然略显简单,但有助于我们理解核心思想。等基础架构搭建完成后,再深入研究实现中那些需要特别注意的细节问题。这个初始版本存在(虽微小但危险的)缺陷,切勿直接用于生产环境(本章后续我们会提供正确的实现版本)。
建议各位读者可以先自行尝试找出这个实现中的“粗糙之处”,本章后面我们会详细讨论这些问题。
8.3.1 会计员单例类
Accountant类将具体实现单例设计模式,其作用是让全局重载的内存分配操作符,能够追踪程序中动态分配的内存字节数。单例模式的核心在于:确保程序中某个类只有一个实例。这个概念可以在各种支持面向对象范式的语言中,以符合各自特点的方式实现。
C++的一个关键特性在于用户代码中操作的是实际对象(而非对象引用),因此C++的单例通常具有以下特征:
私有默认构造函数(若为公有则可多次调用,破坏单例性)
删除复制操作(防止通过复制产生多个实例)
提供受控的实例创建/访问机制(我们选择静态成员函数实现)
包含单例对象的状态表示和功能服务
Accountant类将提供3项服务:
- new/new[]操作符通知内存分配
- delete/delete[]操作符通知内存释放
- 用户端可查询当前内存使用量
根据当前讨论,Accountant类的初步设计如下(非完整实现):
#ifndef LEAK_DETECTOR_H
#define LEAK_DETECTOR_H
#include <cstddef>
#include <new>
class Accountant {
Accountant(); // 注意:构造函数是私有的
//...
public:
// 删除复制构造函数和赋值运算符
Accountant(const Accountant&) = delete;
Accountant& operator=(const Accountant&) = delete;
// 获取单例对象
static Accountant& get();
// 提供的服务:
// 已分配 n 个字节
void take(std::size_t n);
// 已释放 n 个字节
void give_back(std::size_t n);
// 当前已分配的字节数
std::size_t how_much() const;
};
// 全局内存分配/释放操作符(独立函数)
void *operator new(std::size_t);
void *operator new[](std::size_t);
void operator delete(void*) noexcept;
void operator delete[](void*) noexcept;
#endif至此,已经完成本章早前展示的测试程序框架:
#include "leak_detector.h"
#include <iostream>
int main() {
auto pre = Accountant::get().how_much();
{ // BEGIN
int *p = new int{ 3 };
int *q = new int[10]{ }; // 初始化为0
delete p;
// 不好! 忘记“delete[] q”了
} // END
auto post = Accountant::get().how_much();
// 假设 sizeof(int) == 4,我们期望看到输出 "Leaked 40 bytes"
if(post != pre)
std::cout << "Leaked " << (post - pre) << " bytes\n";
}现在,需要研究Accountant类的具体实现。首要问题是,如何及在何处创建实际单例对象。事实上存在多种实现方式,但在我们(不特别关注执行速度的)场景下,最简洁可靠的方式是采用Meyers单例模式 —— 该模式以现已退休但仍备受尊敬的Scott Meyers命名,他在经典著作《Effective C++: Specific Ways to Improve Your Programs and Designs (第三版)》(Addison-Wesley Professional出版)的第47条中提出了这一技术。
Meyers单例技术旨在避免静态初始化顺序灾难(指在多编译单元的C++程序中,全局对象的构造顺序无法通过源码确定的问题,该问题同样存在于析构顺序中,不过Meyers技术对此无效)。其精髓在于:将单例对象声明为访问函数(本例中的get()函数)内的静态局部变量。这样做能确保:
对象仅在函数首次调用时创建一次
对象状态在程序执行期间持续保持
通过底层隐式同步机制保障多线程环境下的安全构造
这种技术能确保所有单例按正确顺序创建(即当单例A的构造函数需要调用单例B的服务时,单例B会“即时”构造),只要它们之间不存在循环依赖,即便其本质上是“全局”变量。不过,这种机制会带来微小但可测量的性能开销。
状态管理方面,由于take()和give_back()都接受std::size_t类型的参数,可以直接用std::size_t表示当前内存量。但我有更好的方案:std::size_t是无符号整型的别名,这种表示法难以检测“释放字节数超过分配数”的异常情况 —— 这种错误恰恰需要处理。因此,将采用(大容量)有符号整型来记录,或许直接使用long long即可,但请注意:内存分配/释放机制需要保证线程安全,必须确保对该整型的所有访问都是同步的。虽然实现方式很多,但最简单的方案是使用原子类型 —— 这里选择std::atomic<long long>。需要说明的是,原子类型本身不可复制,因此我们的单例类已隐式具备不可复制性。不过像之前显式删除复制操作一样,明确声明这点也无妨。
完整的Accountant类实现如下:
#ifndef LEAK_DETECTOR_H
#define LEAK_DETECTOR_H
#include <cstddef>
#include <atomic>
#include <new>
class Accountant {
std::atomic<long long> cur;
Accountant() : cur{ 0LL } { // 注意为私有
}
public:
// 删除复制操作
Accountant(const Accountant&) = delete;
Accountant& operator=(const Accountant&) = delete;
// 用于访问单例对象
static auto& get() { // 为了简化写法使用 auto
static Accountant singleton; // 这就是那个单例对象
return singleton;
}
// 该对象提供的服务
// 已分配 n 个字节
void take(std::size_t n) { cur += n; }
// 已释放n 个字节
void give_back(std::size_t n) { cur -= n; }
// 当前已分配的字节数
std::size_t how_much() const { return cur.load(); }
};
// 全局内存分配/释放操作符(独立函数)
void *operator new(std::size_t);
void *operator new[](std::size_t);
void operator delete(void*) noexcept;
void operator delete[](void*) noexcept;
#endif这些服务功能大部分都容易理解。由于cur是原子对象,像+=和-=这样的操作会以同步方式修改cur,从而避免数据竞争。how_much()有两个细节值得讨论:
返回的是cur.load()而非cur本身,因为我们关心的是原子对象表示的数值,而非原子对象这个同步机制(如前所述,原子对象不可复制)。这就像在特定时刻,给这个值拍了一张照片(快照)。
由此带来的结果是:当使用端代码获取这个返回值时,实际值可能已经改变。因此在多线程环境下使用这个函数本质上是存在“竞态条件”的。当然,对我们的测试代码来说不是问题,但需要注意这一点。
现在,已经搭建好了跟踪分配字节数的框架,可以开始编写实际的分配和释放函数了。
8.3.2 实现new与new[]操作符
根据设计方案,内存分配操作符将执行以下操作:获取使用端代码请求的字节数n,然后实际分配稍大的内存块 —— 会在返回给客户端的n字节内存块起始位置之前隐藏n值,至少需要分配n + sizeof(n)字节才能实现这一点。本示例中,将使用std::malloc()和std::free()执行底层内存操作。
按照C++惯例,将通过抛出std::bad_alloc来通知分配失败。若分配成功,即使实际分配了更多内存,也只向Accountant对象报告n字节的分配量。这种策略导致的实际超额分配是内部实现细节,既不会影响使用端代码,也可能在诊断问题时造成困惑 —— 比如,仅分配1字节却显示泄漏了更多内存的情况会显得很不合理。
以下是完整且略显简单(且如前所述存在些许问题)的实现:
#include <cstdlib>
void *operator new(std::size_t n) {
// 分配 n 个字节,再加上足够的空间用于隐藏 n 的值
void *p = std::malloc(n + sizeof n); // 待修改
// 如有必要,表示未能满足后置条件(即分配失败)
if(!p) throw std::bad_alloc{};
// 在分配的内存块开头“隐藏” n 的值
auto q = static_cast<std::size_t*>(p);
*q = n; // 待修改
// 通知内存统计器(Accountant)这次内存分配
Accountant::get().take(n);
// 返回请求的内存块的起始位置
return q + 1; // 待修改
}
void *operator new[](std::size_t n) {
// 与上面的 operator new 完全相同
}虽然本例中operator new()和operator new[]()实现完全相同,但并非所有场景都必须如此。同时代码中标注“待修改”的部分,将在本章后续深入探讨。
8.3.3 实现delete与delete[]操作符
释放操作符将与分配操作符精心设计的“谎言”密切配合:虽然new和new[]操作符返回的是指向n字节内存块的指针,但这个内存块并非实际分配的全部空间 —— 仅是对象短暂栖息的场所。因此,delete和delete[]操作符在执行实际释放前,必须进行必要的地址调整。
正确实现释放操作符的规则:
对空指针应用operator delete()或operator delete[]()应无操作
释放函数不得抛出异常
释放代码必须与对应的分配函数逻辑一致
对于某个类型为T*的对象p而言,当p==nullptr时执行delete p或delete[] p确实是无操作(no-op)。但直接写delete nullptr会导致编译失败,因为nullptr是std::nullptr_t类型的对象而非指针。
基于前文实现的分配操作符,可以编写一个基本可用的释放操作符:
void operator delete(void *p) noexcept {
// 对空指针执行 delete 是一个无操作(不会产生任何效果)
if(!p) return;
// 找到最初分配的内存块的起始位置
auto q = static_cast<std::size_t*>(p) - 1; // 待修改
// 通知内存统计器(Accountant)这次内存释放操作
Accountant::get().give_back(*q);
// 释放内存
std::free(q);
}
void operator delete[](void *p) noexcept {
// 与上面的 operator delete 完全相同
}至此,我们完成了这个“谎言”的闭环(可以这么说),也完成了内存泄漏检测器的初版实现 —— 尽管它尚不完美。如果在sizeof(int)==4的编译器上运行测试程序,将看到程序如预期般报告泄漏了40字节内存。
8.3.4 整体可视化
进行这类底层编程时(接管程序的内存分配函数、操作原始内存块、隐藏信息、对地址进行各种技巧性操作),往往很难直观地理解当前操作及其实际影响。
如果调试器支持,建议逐步单步执行测试程序。请确保在“debug”(非优化)模式下操作,这样才能充分观察执行过程 —— 优化后的代码通常经过编译器深度转换,难以建立源码与生成代码之间的对应关系。
让我们逐步跟踪operator new()的调用过程:首先在main()函数开头通过Accountant查询当前动态内存分配量。
int main() {
auto pre = Accountant::get().how_much();
{ // BEGIN
int *p = new int{ 3 };
int *q = new int[10]{ }; // 初始化为0
delete p;
// 不好! 忘记了“delete[] q”
} // END
auto post = Accountant::get().how_much();
if(post != pre)
std::cout << "Leaked " << (post - pre) << " bytes\n";
}此时pre的值预期为0,但某些情况下(例如全局对象在其构造函数中调用new)可能导致pre出现非零值。这并无妨,因为我们监控的是BEGIN和END标记之间的内存泄漏情况,无论这两个标记之外分配了多少内存都不影响检测结果。
下一步是调用operator new()申请存储一个int对象所需的内存块:
int main() {
auto pre = Accountant::get().how_much();
{ // BEGIN
int *p = new int{ 3 };
int *q = new int[10]{ }; // 初始化为0
delete p;
// 不好! 忘记了“delete[] q”
} // END
auto post = Accountant::get().how_much();
if(post != pre)
std::cout << "Leaked " << (post - pre) << " bytes\n";
}这将进入operator new()实现,其中n==sizeof(int)。假设本例中sizeof(int)==4且sizeof(std::size_t)==8,那么调用std::malloc()至少会申请12字节的内存块:
void *operator new(std::size_t n) {
void *p = std::malloc(n + sizeof n);
if(!p) throw std::bad_alloc{};
auto q = static_cast<std::size_t*>(p);
*q = n;
Accountant::get().take(n);
return q + 1;
}如果用调试器查看std::malloc()返回后p指向的内存,可能会看到如下内容(所有数值以十六进制表示):

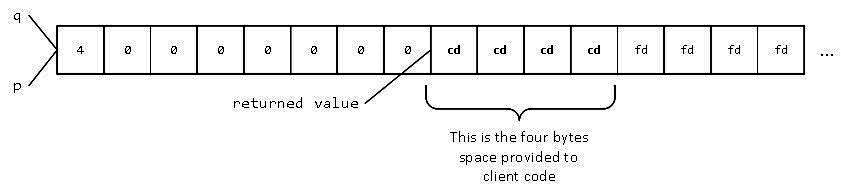
这些具体数值并不具有确定性,C++标准未对std::malloc()返回内存块的初始状态作任何要求。但在“debug构建”模式下,出现0xcd这类十六进制值或类似可识别模式是常见现象 —— 调试版库通常会在未初始化内存中填充特殊位模式,以辅助检测程序错误。
可能还会注意到末尾的四个字节(每个包含0xfd),这些同样显露出可识别的特征模式,这表明我所使用的std::malloc()实现实际分配的内存比请求的更多,并在请求块之后存储了标记 —— 很可能是用于检测缓冲区溢出。毕竟,标准库和我们一样享有这种实现自由!
我们撒的第一个谎是关于内存总量的超额分配,现在我们要撒第二个谎了:
void *operator new(std::size_t n) {
void *p = std::malloc(n + sizeof n);
if(!p) throw std::bad_alloc{};
auto q = static_cast<std::size_t*>(p);
*q = n;
Accountant::get().take(n);
return q + 1;
}如第3章所述,使用static_cast可以高效完成void*指针的类型转换。现在我们对该内存块有两种视角:p声称它持有原始内存,而q则(错误地)声称其至少存储着一个std::size_t类型的数据。

通过q指针,在分配内存块的起始处隐藏了n的值。这并非将返回给调用者的部分,这一操作是在使用端代码不知情的情况下完成的:
void *operator new(std::size_t n) {
void *p = std::malloc(n + sizeof n);
if(!p) throw std::bad_alloc{};
auto q = static_cast<std::size_t*>(p);
*q = n;
Accountant::get().take(n);
return q + 1;
}此时p和q指向的内存可能呈现如下状态:

再次提醒,各位读者看到的结果可能与此不同:我们写入了一个8字节整数值(这解释了为何连续多个字节被修改),但整数的字节序取决于底层硬件架构 —— 大端序架构将整数的最高有效字节存储在最低内存地址,而小端序架构则相反。在单机程序中通常不会察觉这种差异,除非涉及数据持久化存储或网络传输。其他机器上,可能会看到数值4出现在这8字节写入区域的右侧,而非本例所示的左侧位置。
在向Accountant报告分配了4字节(而非实际分配的12字节)后,将返回使用端实际请求的4字节内存块的起始地址:
void *operator new(std::size_t n) {
void *p = std::malloc(n + sizeof n);
if(!p) throw std::bad_alloc{};
auto q = static_cast<std::size_t*>(p);
*q = n;
Accountant::get().take(n);
return q + 1;
}观察当前内存块,其状态如下所示:
当控制流返回调用方后,int对象的构造函数将在operator new()返回的内存块上执行:
int main() {
auto pre = Accountant::get().how_much();
{ // BEGIN
int *p = new int{ 3 };
int *q = new int[10]{ }; // 初始化为0
delete p;
// 不好!忘记了“delete[] q”
} // END
auto post = Accountant::get().how_much();
if(post != pre)
std::cout << "Leaked " << (post - pre) << " bytes\n";
}当main()函数中对指针p指向的内存完成构造后,内存块状态可能如下:

其精妙之处在于:使用端代码(即main()函数)完全不知晓我们实施的这些“花招”与“谎言”,就像我们也无从知晓std::malloc()背后的小动作一样(除非查看其源码)。程序继续正常执行,*p可以像普通int变量一样使用,直到执行释放操作:
int main() {
auto pre = Accountant::get().how_much();
{ // BEGIN
int *p = new int{ 3 };
int *q = new int[10]{ }; // 初始化为0
delete p;
// 不好!忘记了“delete[] q”
} // END
auto post = Accountant::get().how_much();
if(post != pre)
std::cout << "Leaked " << (post - pre) << " bytes\n";
}进入operator delete()时,参数p指向的内存起始值是整数3(而非之前存储的4)。这是合理的,因为p指向的是返回给使用端的内存块,而非实际分配的完整内存块起始地址:

继续之前,需要说明一个重要细节:这里显示3是因为int作为简单可析构类型,其析构函数实质是空操作。通常当operator delete()开始执行时,指向对象的析构函数已完成调用,此时内存块可能包含任意数据。
在operator delete()内部,首要任务是定位当初调用operator new()时隐藏的n值存储位置:
void operator delete(void *p) noexcept {
if(!p) return;
auto q = static_cast<std::size_t*>(p) - 1;
Accountant::get().give_back(*q);
std::free(q);
}此时,q指向的位置既是存储n值的地方,也是实际分配内存块的起始地址。我们向Accountant报告释放了n字节,并调用std::free()执行实际释放操作。
当调用std::free()时,如果观察q指向的内存,可能会(但不保证)看到该内存覆写。同样可能(也不保证)看到q之前。以及分配内存块末端之后的内存也会修改。请记住,std::free()和std::malloc()一样,可以执行任何必要的簿记操作 —— 特别是在调试版本中,可能会覆写已释放的内存块;而在优化版本中,更可能保持内存原状。
这个过程很有趣,不是吗?至少在部分机器上,这套机制似乎运行良好。但如前所述,当前版本的泄漏检测器存在缺陷,这些缺陷可能造成严重问题。举个例子:如果在std::size_t为4字节宽的编译器上编译此检测器,并尝试new double操作,就可能引发严重错误。现在,需要仔细审查实现代码,找出问题根源并进行修复。