12.4. 高效内存管理策略
有位谦逊的作者声称,我们这个 nice 但简单的 Vector<T> 类型根本无法与 std::vector<T> 相媲美。
这听起来似乎是一个大胆的说法:毕竟,我们似乎完成了所需的功能,而且更不用说,使用了算法而不是原始循环;捕捉了异常,以实现异常安全,只是将自己限制在清理资源上……我们到底哪里做错了?如果在 Vector<int> 对象和 std::vector<int> 对象之间运行对比基准测试,可能不会注意到两者在性能数据上有什么显著差异。
例如,尝试向这两个容器中各添加一百万个 int 对象(通过 push_back()),可能我们的容器表现得还不错。太棒了!现在,将测试对象改为 Vector<std::string> 和 std::vector<std::string> 的对比测试,可能会有点失望,会发现我们被远远地“甩在了后面”。
如果添加的字符串不是太短的(比如说,尝试添加 25 个字符以上的字符串),这种优化效果会更加明显。对于“短”字符串(这里的“短”是一个不确定的值),大多数标准库实现都会执行一种称为小字符串优化(Small String Optimization,简称 SSO)的技术,这是小对象优化(Small Object Optimization,简称 SOO)的一个特例。通过这种优化,当需要存储的数据足够小时,实现会将对象所谓的“控制块”(实际上是数据成员)的空间直接用作原始存储空间,从而避免了动态内存分配。正因为如此,“小”字符串不会引发内存分配操作,在实际运行中速度非常快。
但这是为什么呢?
两次测试中元素类型的差异提供了一个线索:int 是一个简单可构造(trivially constructible)的类型,而 std::string 不是。这表明,std::vector 可能调用的构造函数比我们更少,它在处理内存和其中对象的方式上比我们的 Vector<T> 更高效。
问题出在哪里呢?来看看 Vector<T> 的一个构造函数,从而更好地理解这个问题。除了默认构造函数(在实现中使用了默认实现)和移动构造函数之外,任何一个构造函数都可以说明问题。因此,来看那个接受元素个数和初始值作为参数的构造函数。请特别注意“高亮代码”部分:
// ...
Vector(size_type n, const_reference init)
: elems{ new value_type[n] }, // 高亮代码
nelems{ n }, cap{ n } {
try {
std::fill(begin(), end(), init); // 高亮代码
} catch(...) {
delete [] elems;
throw;
}
}
// ...elems 数据成员的构造会分配一块足够容纳 n 个类型为 T 的对象的内存块,并为这 n 个元素中的每一个调用默认构造函数。如果 T 是简单可构造(trivially constructible)的类型,这些默认构造函数不会带来太大的困扰,但如果 T 不可简单构造,这么做的合理性就值得怀疑了。
尽管可能会争辩说这些对象终究是需要构造,但请再仔细看看后续代码,会发现 std::fill() 会用 init 的副本替换掉这些默认构造出的 T 对象。最初对这些对象的默认构造本质上是一种时间的浪费(根本就没有使用这些对象!)。
这正是 std::vector<T> 比我们做得好得多的地方:避免了这些浪费的操作,仅执行必要的步骤。
12.4.1 更高效的Vector<T>
更高效的 Vector<T> 的关键在于区分分配与构造,这在这本书中多次讨论过的内容。还有,就是在适当的场合以受控的方式“欺骗”类型系统,那些早期章节的内容现在就要派上用场了。
我们不会在这部分内容中重写整个 Vector<T>,但会挑选一些成员函数进行讲解,以突出需要执行的操作(完整的实现可以在本章开头提到的 GitHub库中找到)。
可以尝试手动完成这一工作,使用已经了解的语言特性,例如 std::malloc() 来分配一块原始内存区域,并使用定位 new(placement new)在这块内存中构造对象。以一个接受元素数量和初始值作为参数的构造函数为例,将得到如下代码:
// ...
Vector(size_type n, const_reference init)
// A
: elems{ static_cast<pointer>(
std::malloc(n * sizeof(value_type)
) }, nelems{ n }, cap{ n } {
// B
auto p = begin(); // 注意: 已知p的类型是T*
try {
// C
for(; p != end(); ++p)
new(static_cast<void*>(p)) value_type{ init };
} catch(...) {
// D
for(auto q = begin(); q != p; ++q)
q->~value_type();
std::free(elems);
throw;
}
}
// ...这……有点糟糕了。请注意函数中标注从 A 到 D 的这几个部分:
在 A 部分,进行了第一个“谎言”:分配了足以容纳 n 个类型为 T 的对象的存储空间,但仅限于原始内存的分配(此时还没有调用任何 T 对象的构造函数),仍然使用了一个 T* 指针指向这块内存。我们的实现需要在内部意识到,此时 elems 指针的类型不正确。
在 B 部分,调用了 begin(),我们知道在我们的实现中 iterator 就等同于 T*。如果实现使用了一个类而不是原始指针来表示迭代器,就需要在这里做一些工作,以获取指向原始内存块的底层指针,从而实现函数的其余部分。
在 C 部分,在已分配的内存块中就地构造 T 类型的对象。由于这些内存位置上原本没有对象可以替换,所以使用定位 new(placement new)来构造这些对象,并利用了对类型系统的“欺骗”(即使用 T* 指针,但分配的是原始内存),从而进行所需的指针运算,以便在各个对象之间移动。
在 D 部分,处理可能由 T 类型对象的构造函数抛出的异常。由于只有我们自己知道内存中有哪些 T 对象存在,就像只有自己知道第一个构造失败的对象在哪里一样,所以需要手动销毁这些对象,然后释放(此时已经是原始内存的)内存块,并重新抛出异常。此外,这个实现甚至不满足标准的一致性要求;应该按照构造顺序的逆序来销毁对象,而这个例子并没有这么做。
顺便提一下,这个例子清楚地说明了,为什么不能从析构函数中抛出异常:如果在 D 部分抛出了异常,几乎无法合理地进行恢复(至少在不产生高昂代价的前提下)。
亲爱的读者,现在可能正觉得这种方式过于复杂,而且充满了错误隐患,非专家人士根本不可能指望用这种方式写出一整个容器。确实如此,这种复杂性会渗透到大量的成员函数中,使得质量控制远比你期望的要困难得多。
但还有希望!库的开发者们面临的挑战比我们更多,所以标准库提供了一些底层设施,使得只要你了解了本书到目前为止所讲的内容,就能以一种合理可行的方式来处理自制容器中的原始内存。
12.4.2 使用底层标准设施
标准库头文件 <memory> 对于涉足内存管理的开发者来说是一个充满有用设施的宝库。我们已经讨论过该头文件中定义的标准智能指针(参见第 5 章以回顾相关内容),如果深入了解一下就会发现,其中还包含一些用于操作原始内存的算法。
以 Vector<T> 的构造函数为例,该构造函数接受元素数量和初始值作为参数。我们最初实现了一个相当简单的版本:分配一个 T 类型的对象数组,并通过调用 std::fill() 来替换这些元素;而后来改写成了一个复杂得多的版本。最初的版本既简单又低效(构造了一些不必要的对象,只是为了随后替换它们);而替换后的版本效率更高(执行的工作最少),但编写和维护它需要更高的技巧。
现在,将研究这些工具对我们实现的“分配型”成员函数所带来的影响。首先关注构造函数,这是一个很好的起点。
对构造函数的影响
实际上,当想要编写一个自行管理内存的自制容器时,最好使用 <memory> 中提供的底层设施:
// ...
Vector(size_type n, const_reference init)
: elems{ static_cast<pointer>(
std:malloc(n * sizeof(value_type))
) }, nelems{ n }, cap{ n } {
try {
std::uninitialized_fill(begin(), end(), init);
} catch(...) {
std::free(elems);
throw;
}
}
// ...这个版本比起我们手动编写的版本要清晰优雅得多,不是吗?这个版本有两个亮点:
分配了一块大小合适的原始内存块,而不是一个 T 类型对象的数组,从而避免了初始版本中不必要的默认构造函数调用。
将原本使用 std::fill()(定义在
中)的调用替换为 std::uninitialized_fill()。std::fill() 使用 T::operator=(const T&),所以赋值操作左侧必须已经存在一个构造好的对象;而 std::uninitialized_fill() 则假设它操作的是原始内存,并通过placement new来初始化对象。
这个算法(以及同一系列的其他算法)的妙处在于异常安全。如果 std::uninitialized_fill() 调用的某个构造函数抛出了异常,那么在异常离开函数之前,之前成功构造的所有对象都会销毁(按照构造顺序的逆序销毁)。
这其实就是我们之前手动实现的功能,只不过当初写得比较笨拙。除了现在自己负责分配和释放原始内存之外,其余的代码与最初的简单版本非常相似。
其他构造函数也可以采用类似的实现方式。例如,复制构造函数就可以这样实现:
// ...
Vector(const Vector& other)
: elems{ static_cast<pointer>(
std::malloc(n * sizeof(value_type))
) },
nelems{ other.size() }, cap{ other.size() } {
try {
std::uninitialized_copy(
other.begin(), other.end(), begin()
);
} catch (...) {
std::free(elems);
throw;
}
}
// ...有了合适的算法,那些操作原始内存的高效实现,与那些简单但较慢的版本非常相似。
这里的关键是要理解 API 的边界。像 std::uninitialized_copy() 这样的函数接受三个参数:源序列的起始和结束位置(该序列被认为包含的是已构造的对象),以及目标序列的起始位置(该序列认为具有合适的对齐方式,并且由原始内存组成,而不是对象)。如果该函数成功执行完毕,并满足了它的后置条件(即在目标序列中构造了对象),那么目标序列现在就包含对象。另一方面,如果函数未能满足其后置条件,那么目标序列中就不会有任何对象 —— 函数在退出前会销毁它所构造的所有内容。
其他构造函数也可以采用类似的处理方式,需要注意的是,默认构造函数和移动构造函数的实现方式差异很大,因此也应区别对待。
对析构函数的影响
在 Vector<T> 的实现中,析构函数的设计很有意思:当对象到达生命周期的终点时,不能简单地对 elems 成员调用 delete[],因为它一开始并不是通过 new[] 分配的,而且它指向的是一段包含多个 T 类型对象的内存,这段内存之后可能还跟着一段原始字节(raw bytes)。当然不能对任意的字节序列调用 T::~T(),这可能会对程序造成严重破坏,并导致未定义行为(UB)。
唯一知道容器中实际存在多少个对象的实体就是 Vector<T> 自身对象,它必须先对所有仍然存在的对象调用析构函数 destroy(),然后才能调用 free() 来释放这块现在已经不再包含任何对象的内存。对一段 T 类型对象的序列调用 std::destroy() 算法,会逐个调用每个对象的析构函数 T::~T(),从而将这段对象序列转化为原始内存:
// ...
~Vector() {
std::destroy(begin(), end());
std::free(elems);
}
// ...这些底层的内存管理算法,在表达我们所编写代码的意图方面确实起到了很大帮助。
对插入函数的影响
类似的情况也出现在 push_back() 和 emplace_back() 这两个成员函数中:以前通过赋值操作替换数组末尾的某个已有对象;而现在,由于数组末尾不再有任何对象(不会无故构造对象),需要在数组末尾构造一个新对象。
显然可以使用placement new来完成这一操作,但标准库提供了一个在语义上等价的函数,名为 std::construct_at()。这使得我们的意图在源码中更加清晰明了:
// ...
void push_back(const_reference val) {
if (full())
grow();
std::construct_at(end(), val);
++nelems;
}
void push_back(T&& val) {
if (full())
grow();
std::construct_at(end(), std::move(val));
++nelems;
}
template <class ... Args>
reference emplace_back(Args &&...args) {
if (full())
grow();
std::construct_at(
end(), std::forward<Args>(args)...
);
++nelems;
return back();
}对增长函数的影响
我们最初实现的 grow() 函数调用了 Vector<T> 的 resize() 函数,但 resize() 的作用是对存储空间用对象进行初始化。如果希望让已分配的存储空间增长,但又不进行对象的初始化,就需要一个不同的成员函数,那就是 reserve()。
resize() 可能会在容器中添加对象,可以修改 size() 和 capacity()。而 reserve() 并不会向容器中添加对象,仅限于增加容器所使用的存储空间;换句话说,reserve() 可以改变 capacity(),但不会改变 size()。
遵循 std::vector<T> 所设定的示例,Vector<T> 类也将同时提供 resize() 和 reserve()。下面是一个适配了我们这种“部分是对象、部分是原始内存”结构的 resize() 版本,以及适合 Vector<T> 的 reserve() 实现。
我们将分别讨论 reserve() 和 resize():
// ...
private:
void grow() {
reserve(capacity()? capacity() * 2 : 16);
}
public:
void reserve(size_type new_cap) {
if(new_cap <= capacity()) return;
auto p = static_cast<pointer>(
std::malloc(new_cap * sizeof(T))
);
if constexpr(std::is_nothrow_move_assignable_v<T>) {
std::uninitialized_move(begin(), end(), p);
} else try {
std::uninitialized_copy(begin(), end(), p);
} catch (...) {
std::free(p);
throw;
}
std::destroy(begin(), end());
std::free(elems);
elems = p;
cap = new_cap;
}
// ...reserve() 成员函数首先会确保请求的新容量大于当前容量(否则无需任何操作)。如果确实如此,它将分配一块新的内存区域,并将 Vector<T> 中现有的元素移动或复制到这块新内存中(如果移动 T 对象可能抛出异常,则会执行复制:将移动操作设为 noexcept 也是值得的!),这一过程使用的是能够在原始内存中构造对象的算法。
接着,elems 中原有的 T 对象将销毁(即使它们已经移动过,依然需要正确析构),然后确保更新 cap 并让 elems 指向新的内存块。
由于没有向容器中添加任何新对象,所以size() 并不会改变。
对于 resize() 的处理过程是类似的(如下所示),区别在于:从 size() 索引开始的内存位置会初始化为一个默认构造的 T 对象,而不是保留在原始内存状态。因此,size() 会更新,从而导致与调用 reserve() 后的行为具有不同的语义:
// ...
void resize(size_type new_cap) {
if(new_cap <= capacity()) return;
auto p = static_cast<pointer>(
std::malloc(new_cap * sizeof(T))
);
if constexpr(std::is_nothrow_move_assignable_v<T>) {
std::uninitialized_move(begin(), end(), p);
} else try {
std::uninitialized_copy(begin(), end(), p);
} catch (...) {
std::free(p);
throw;
}
std::uninitialized_fill(
p + size(), p + capacity(), value_type{}
);
std::destroy(begin(), end());
std::free(elems);
elems = p;
nelems = new_cap;
cap = new_cap;
}
// ...我们正在实现的这种更复杂的结构,明显会对插入(insert())或删除(erase())元素的方式产生影响。
对元素插入(insert())和删除(erase())函数的影响
像 insert() 和 erase() 这样的成员函数必须进行更新,以反映我们对 Vector<T> 对象内部组织结构所做的更改。这并不一定很麻烦(事实上,如果每个函数的语义从一开始就很清晰,所需的修改甚至可以非常微小),但这确实需要小心处理。
以 insert(pos, first, last) 为例,已经不再使用图 12.1 中所描述的简单模型:
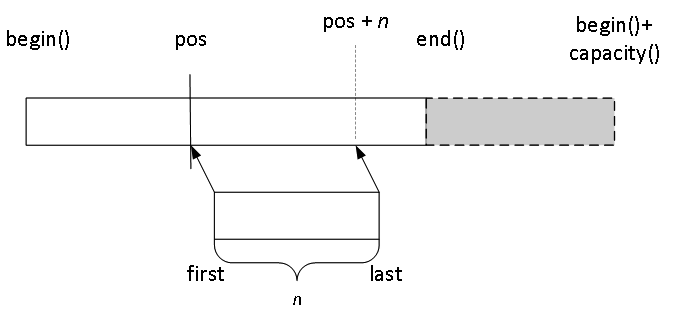
在位置 pos 处插入一个 [first,last) 序列则 [pos,end()) 中的元素(以逆序)复制到 pos + n 位置,然后用 [first,last) 覆盖 [pos,pos+n) 中的元素。
转换到图 12.2 中描述的更复杂模型:
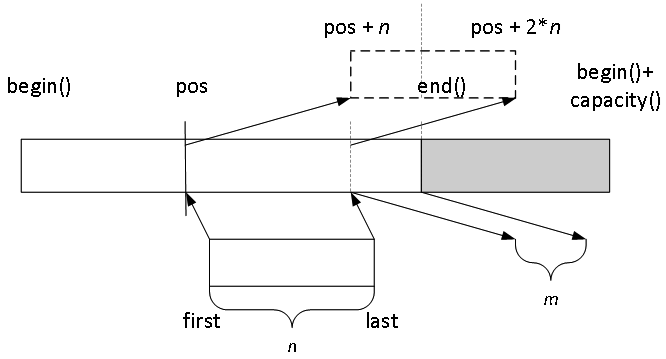
这个想法是我们需要在位置 pos 处插入 [first,last) 序列,所以 [pos,pos+n) 中的元素必须向右复制(或移动)。这将需要在原始内存中构造一些对象(前面图中的灰色区域),并通过复制(或移动)赋值替换一些其他对象。
这里有四个步骤需要考虑:
需要从 [begin(),end()) 序列中复制或移动多少元素到容器末尾的原始内存块中,以及这些对象应在该块中的何处构造。
如果有来自 [first,last) 序列的对象需要插入到原始内存中(可能没有),应该有多少个?如果有这样的对象,它们将在 end() 处插入。
如果有需要从 [pos,end()) 序列复制或移动以替换容器中现有对象的元素(也可能没有),应该有多少个?在这种情况下,目标范围的末端将是 end()。
最后,无论 [first,last) 序列中剩余需要插入的部分都将从 pos 开始在容器中进行复制。
一个可能的实现如下所示:
// ...
template <class It>
iterator insert(const_iterator pos, It first, It last) {
iterator pos_ = const_cast<iterator>(pos);
const auto remaining = capacity() - size();
const auto n = std::distance(first, last);
// 我们在这里使用 cmp_less(),因为 remaining 是无符号整数类型,
// 而 n 是有符号整数类型
if (std::cmp_less(remaining, n)) {
auto index = std::distance(begin(), pos_);
reserve(capacity() + n - remaining);
pos_ = std::next(begin(), index);
}
// 需要从 [begin(),end()) 序列移动或复制到未初始化内存的对象
const auto nb_to_uninit_displace =
std::min<std::ptrdiff_t>(n, end() - pos_);
auto where_to_uninit_displace =
end() + n - nb_to_uninit_displace;
if constexpr(std::is_nothrow_move_constructible_v<T>)
std::uninitialized_move(
end() - nb_to_uninit_displace, end(),
where_to_uninit_displace
);
else
std::uninitialized_copy(
end() - nb_to_uninit_displace, end(),
where_to_uninit_displace
);
// 需要从 [first, last) 插入到未初始化内存的对象(注意:可能没有)
const auto nb_to_uninit_insert =
std::max<std::ptrdiff_t>(
0, n - nb_to_uninit_displace
);
auto where_to_uninit_insert = end();
std::uninitialized_copy(
last - nb_to_uninit_insert, last,
where_to_uninit_insert
);
// 需要从 [pos,end()) 序列移动或复制到该空间的对象(注意:可能没有)
const auto nb_to_backward_displace =
std::max<std::ptrdiff_t>(
0, end() - pos_ - nb_to_uninit_displace
);
// 注意:这是目标位置的末尾
auto where_to_backward_displace = end();
if constexpr (std::is_nothrow_move_assignable_v<T>)
std::move_backward(
pos_, pos_ + nb_to_backward_displace,
where_to_backward_displace
);
else
std::copy_backward(
pos_, pos_ + nb_to_backward_displace,
where_to_backward_displace
);
// 需要从 [first,last) 复制到 pos 的对象
std::copy(
first, first + n - nb_to_uninit_insert, pos
);
nelems += n;
return pos_;
}请确保不要移动 [first, last) 范围内的元素,那样移动会破坏源范围中的数据,对用户不友好!
至于我们最初以一种更简单的方式编写的 erase() 成员函数,需要做出的关键调整在于如何处理移除的元素。你可能还记得,在我们简单版本中,在容器末尾给被擦除的元素赋了一个默认的 T 值,并且指出这会带来一个可疑的要求,即类型 T 必须具有默认构造函数。这个改进的版本中,将非常简单直接地销毁该对象,结束其生命周期,并将其底层存储空间变回原始内存:
iterator erase(const_iterator pos) {
iterator pos_ = const_cast<iterator>(pos);
if (pos_ == end()) return pos_;
std::copy(std::next(pos_), end(), pos_);
std::destroy_at(std::prev(end()));
--nelems;
return pos_;
}希望这能让您对编写一个更严谨的自制 std::vector 类型的实现有更深入的理解,并能更加欣赏那些在您喜爱的标准库实现背后的开发者的精湛技艺。要知道,他们为了让我们编写的程序能够如此高效,所做的远不止这些!
12.4.3 常量成员或引用成员与 std::launder()
结束本章之前,需要简要谈谈那些比较特殊的容器 —— 存储的是 const 类型的对象,或者其元素类型的成员包含 const 或引用类型的成员。
请看下面这个看似无害的程序:
// ...
int main() {
Vector<const int> v;
for(int n : { 2, 3, 5, 7, 11 })
v.push_back(n);
}根据目前的实现,这个程序将无法通过编译,因为实现调用了一些底层函数(如 std::free()、std::destroy_at()、std::construct_at() 等),这些函数的参数都是指向非 const 类型的指针。
如果希望支持这样的程序,则需要再实现中的某些地方必须“去掉”const 属性。例如,将以下这一行:
std::free(elems); // 若元素为const指针则非法替换为:
using type = std::remove_const_t<value_type>*;
std::free(const_cast<type>(elems));同样地,如果容器支持在已有对象存在的情况下进行插入操作,像使用 std::copy() 或 std::copy_backward() 算法所执行的那种赋值操作,在 const 对象或含有 const 成员的对象上将无法正常工作。可以通过用“先销毁再构造”的方式替代直接赋值来让程序运行,但如果在旧对象被销毁之后、新对象尚未成功构造之前发生了异常,代码将变得不够异常安全。
当然,去掉 const 属性会进入危险区域,已经接近了未定义行为的边界。标准库的实现者当然可以随心所欲地这么做,他们与编译器实现者有着密切联系;但我们这些普通开发者却没有这样的特权,因此必须格外小心。
当容器中包含引用类型成员的对象时,也会出现类似的问题:你不能创建一个存储引用的容器(因为引用不是对象),但你完全可以创建一个包含引用类型成员的对象的容器。问题的关键在于,当一个含有引用成员的对象被替换时,我们如何理解其行为。
为了说明这种情况,这里用一个比 Vector<T> 更简单的类来解释。假设有如下类,用于持有一个类型为 T 的对象的引用:
#include <type_traits>
template <class T>
struct X {
static_assert(std::is_trivially_destructible_v<T>);
T &r;
public:
X(T &r) : r{ r } {
}
T& value() { return r; }
const T & value() const { return r; }
};
// ...这个类足够简单,也容易理解和推理。现在,假设有如下使用端代码:
// ...
#include <iostream>
#include <new>
int main() {
int n = 3;
X<int> h{ n };
h.value()++;
std::cout << n << '\n'; // 4
std::cout << h.value() << '\n'; // 4
int m = -3;
// h = X<int>{ m }; // 无法编译
X<int> *p = new (static_cast<void*>(&h)) X<int>{ m };
std::cout << p->value() << '\n'; // -3
// UB (-3? 4? 或其他?)
std::cout << h.value() << '\n';
std::cout << std::launder(&h)->value() << '\n'; // -3
}目前看来,通过赋值操作来替换一个 X<int> 对象并不正确,该类包含一个引用类型的成员,这会删除默认的赋值操作符(至少默认情况下是这样)。默认的赋值语义是不明确的:应该将引用重新绑定到另一个对象,还是应该对所引用的对象进行赋值?
解决这个问题的一种方法是:销毁原始对象,并在其原有位置构造一个新的对象。在例子中,由于通过 static_assert 确保了类型 T 可以简单销毁,因此只是在原来的位置构造了一个新对象(从而结束了原对象的生命周期)。这样一来,内存中的比特位(bits)就会正确映射到了新对象上……但编译器可能并不会认同我们的这种推理。
实际上,编译器会尽可能地追踪对象的生命周期,但我们把自己置于了一种原始 X<int> 对象从未显式销毁的情况中。因此,编译器可能仍然认为那个原始的 X<int> 对象还“在那儿”,但其底层的比特位已经手动替换成了一个新对象的内容。这就可能导致比特位所表达的内容,与编译器从源码中理解的内容之间存在差异,因为(老实说)我们使用了一些“小把戏” —— 在某个特定地址显式构造了一个对象,而那个地址恰好之前被另一个对象所占用。
通过指针 p 调用 value() 肯定会返回 -3,因为很明显 p 指向的是一个 X<int> 对象,持有一个对 m 的引用,而此时 m 的值是 -3。但通过 p2 调用 value() 则是未定义行为(最终得到的是比特位所表达的结果,还是编译器根据源码推断出的结果?)。
这种看起来很邪门的情况 —— 即编译器对代码逻辑的理解与内存中的比特位所表达的内容不一致 —— 会出现在以下几种类型中:包含 const 成员的对象、包含引用成员的对象,以及一些以奇怪方式构造的联合体(union)。但这些正是我们在底层操作对象时所使用的工具,它们可能隐藏在 std::optional<T>、std::vector<T> 等组件的实现之下。最终,使用这些奇怪类型的错误在于我们自己,但这也是生活的一部分。
当比特位不一定与编译器所能理解的内容一致时,我们可以使用 std::launder()。请谨慎使用这个工具:它是一个优化屏障,其含义是告诉编译器:“编译器啊,你就看内存中的比特位吧;在看这个指针所指向的对象时,忘记你对源码的理解。”当然,这是一个非常危险的工具,必须小心使用,但在某些时候,我们所需要它。